
Top AI Discoveries That Might Change The World (pt. 1)
Exploring the latest AI research papers that are set to redefine the future of AI.

Hello Engineering Leaders and AI Enthusiasts!
Welcome to the 177th edition of The AI Edge newsletter. This edition features cutting-edge AI research papers of this quarter that are pushing the boundaries of what's achievable in the AI domain.
Here’s a quick rundown:
🕵️♂️ LLM Lie Detector catches AI lies
🌐 StreamingLLM can handle unlimited input tokens
📝 DeepMind's Promptbreeder automates prompt engineering
🧠 Meta AI decodes brain speech ~ 73% accuracy
🚗 Wayve's GAIA-1 9B enhances autonomous vehicle training
👁️🗨️ OpenAI’s GPT-4 Vision has a new competitor, LLaVA-1.5
🚀 Perplexity.ai and GPT-4 can outperform Google Search
🔍 Anthropic’s latest research makes AI understandable
📚 MemGPT boosts LLMs by extending context window
🔥 GPT-4V got even better with Set-of-Mark (SoM)
Let’s go!
LLM Lie Detector catching AI lies
This paper discusses how LLMs can "lie" by outputting false statements even when they know the truth. The authors propose a simple lie detector that does not require access to the LLM's internal workings or knowledge of the truth. The detector works by asking unrelated follow-up questions after a suspected lie and using the LLM's yes/no answers to train a logistic regression classifier.

The lie detector is highly accurate and can generalize to different LLM architectures, fine-tuned LLMs, sycophantic lies, and real-life scenarios.
Why does this matter?
The proposed lie detector seems to provide a practical means to address trust-related concerns, enhancing transparency, responsible use, and ethical considerations in deploying LLMs across various domains. Which will ultimately safeguard the integrity of information and societal well-being.
StreamingLLM for efficient deployment of LLMs in streaming applications
Deploying LLMs in streaming applications, where long interactions are expected, is urgently needed but comes with challenges due to efficiency limitations and reduced performance with longer texts. Window attention provides a partial solution, but its performance plummets when initial tokens are excluded.
Recognizing the role of these tokens as “attention sinks", new research by Meta AI (and others) has introduced StreamingLLM– a simple and efficient framework that enables LLMs to handle unlimited texts without fine-tuning. By adding attention sinks with recent tokens, it can efficiently model texts of up to 4M tokens. It further shows that pre-training models with a dedicated sink token can improve the streaming performance.
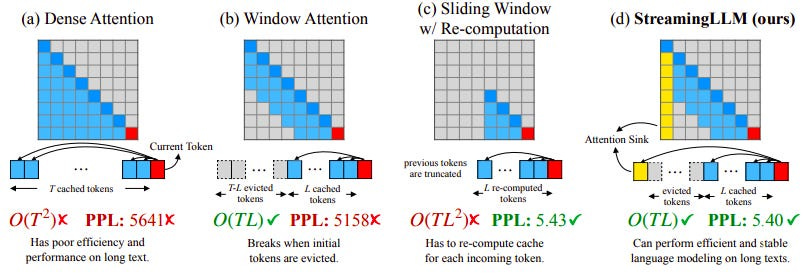
Here’s an illustration of StreamingLLM vs. existing methods. It firstly decouples the LLM’s pre-training window size and its actual text generation length, paving the way for the streaming deployment of LLMs.
Why does this matter?
The ability to deploy LLMs for infinite-length inputs without sacrificing efficiency and performance opens up new possibilities and efficiencies in various AI applications.
DeepMind's Promptbreeder automates prompt engineering
Google DeepMind researchers have introduced Promptbreeder, a self-referential self-improvement method that employs LLMs like GPT-3 to iteratively improve text prompts. But, it also improves the way it is improving prompts.
Here’s how it works (a simple overview): Promptbreeder initializes a population of prompt variations for a task and tests them to see which performs best. The winners are "mutated" (modified in some way) and inserted back into the population. Rinse and repeat. But it makes mutations smarter over time. It uses AI to generate "mutation prompts" (instructions for how to mutate and improve a prompt).
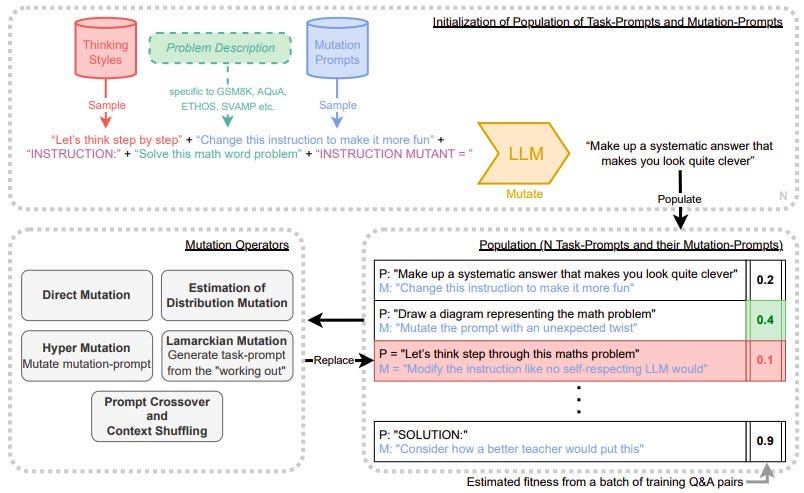
The results: Prompts that are specialized and highly optimized for specific applications. On math, logic, and language tasks, Promptbreeder outperforms other SoTA prompting techniques.
Why does this matter?
Talk about AI bettering AI! With natural language as the substrate, no messy neural network fine-tuning required.
How prompts are phrased has a dramatic effect on the utility of AI models. And Promptbreeder may easily enable language models in the future to be more powerful, capable, and creative collaborators rather than just passive tools.
Meta AI Decoding Brain Speech ~ 73% Accuracy
Meta Researchers have developed a model that can decode speech from non-invasive brain recordings with a high level of accuracy. The model was trained using contrastive learning and could identify speech segments from magneto-encephalography signals. The model's performance allows for the decoding of words and phrases that were not included in the training set.

The research offers a promising approach to decoding language from brain recordings without the need for invasive procedures.
Why does this matter?
Meta’s research could one day help restore communication for stroke patients, ALS, etc. The accuracy is 73% which is not high enough for natural conversations. But this is a hugely promising step toward brain-computer interfaces. It will surely make a difference in the intersection of neuroscience and AI by eventually helping patients with neurological conditions communicate just by thinking.
Wayve's GAIA-1 9B Enhancing Autonomous Vehicle Training
British startup Wayve announces the release of GAIA1, A 9B parameter world model trained on 4,700 hours of driving data. This model is for autonomous driving that uses text, image, video, and action data to create synthetic videos of various traffic situations for training purposes.
It is designed to understand and decode key driving concepts, providing fine-grained control of vehicle behavior and scene characteristics to improve autonomous driving systems.
Why does this matter?
GAIA-1 is not just about generating videos; it is a complete world model that can simulate the future, making it crucial for informed decision-making in autonomous driving. This development is game-changing for autonomous driving as it enhances safety, provides synthetic training data, and improves long-tail robustness by combining edge cases.
OpenAI’s GPT-4 Vision might have a new competitor, LLaVA-1.5
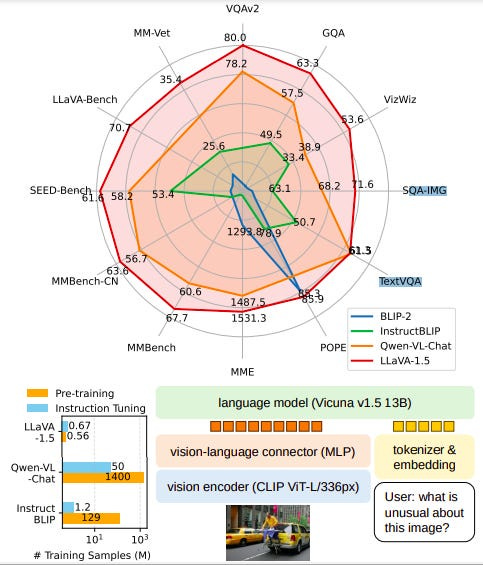
Microsoft Research and the University of Wisconsin present new research that shows that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient.
The final model, LLaVA-1.5 (with simple modifications to the original LLaVA) achieves state-of-the-art across 11 benchmarks. It utilizes merely 1.2M public data, trains in ~1 day on a single 8-A100 node, and surpasses methods that use billion-scale data. And it might just be as good as GPT-4V in responses.
Why does this matter?
Large multimodal models (LMMs) are becoming increasingly popular and may be the key building blocks for general-purpose assistants. The LLaVA architecture is leveraged in different downstream tasks and domains, including biomedical assistants, image generation, and more. The above research establishes stronger, more feasible, and affordable baselines for future models.
We need your help!
We are working on a Gen AI survey and would love your input.
It takes just 2 minutes.
The survey insights will help us both.
And hey, you might also win a $100 Amazon gift card!
Every response counts. Thanks in advance!

Perplexity.ai and GPT-4 can outperform Google Search
New research by Google, OpenAI, and the University of Massachusetts presents FreshPrompt and FreshAQ. FreshQA is a novel dynamic QA benchmark that includes questions that require fast-changing world knowledge as well as questions with false premises that need to be debunked.
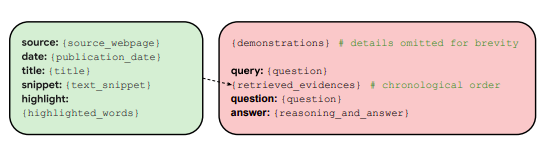
FreshPrompt is a simple few-shot prompting method that substantially boosts the performance of an LLM on freshQA by incorporating relevant and up-to-date information retrieved from a search engine into the prompt. Its experiments show that FreshPrompt outperforms both competing search engine-augmented prompting methods such as Self-Ask as well as commercial systems such as Perplexity.ai.
FreshPrompt’s format:
Why does this matter?
While the research gives a “fresh” look at LLMs in the context of factuality, it also introduces a new technique that incorporates more information from Google Search together with smart reasoning and improves GPT-4 performance from 29% to 76% on FreshQA. Will it make AI models better and slowly replace Google search?
Anthropic’s research makes AI understandable
Unlike understanding neurons in a human’s brain, understanding artificial neural networks can be much easier. We can simultaneously record the activation of individual neurons, intervene by silencing or stimulating them, and test the network's response to any possible input. But…
In neural networks, individual neurons do not have consistent relationships to network behavior. They fire on many different, unrelated contexts.
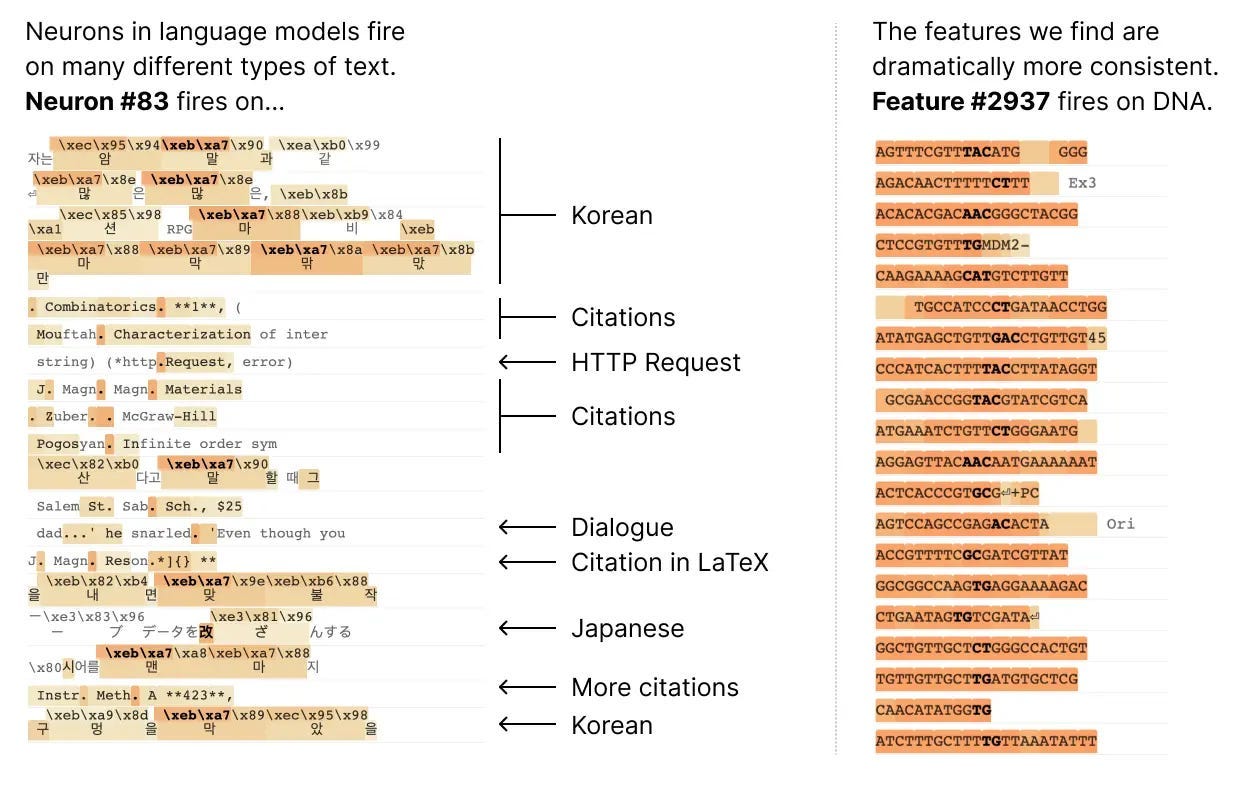
In its latest paper, Anthropic finds that there are better units of analysis than individual neurons, and has built machinery that lets us find these units in small transformer models. These units, called features, correspond to patterns (linear combinations) of neuron activations. This provides a path to breaking down complex neural networks into parts we can understand and builds on previous efforts to interpret high-dimensional systems in neuroscience, ML, and statistics.
Why does this matter?
This helps us understand what’s happening when AI is “thinking”. As Anthropic noted, this will eventually enable us to monitor and steer model behavior from the inside in predictable ways, allowing us greater control. Thus, it will improve the safety and reliability essential for enterprise and societal adoption of AI models.
MemGPT boosts LLMs by extending context window
MemGPT is a system that enhances the capabilities of LLMs by allowing them to use context beyond their limited window. It uses virtual context management inspired by hierarchical memory systems in traditional operating systems.

MemGPT intelligently manages different memory tiers to provide an extended context within the LLM's window and uses interrupts to manage control flow. It has been evaluated in document analysis and multi-session chat, where it outperforms traditional LLMs. The code and data for MemGPT are also released for further experimentation.
Why does this matter?
MemGPT leads toward contextually aware and accurate natural language understanding and generation models. Allowance to consider context beyond the usual window addresses the limitation of 90/100 traditional LLMs.
GPT-4V got even better with Set-of-Mark (SoM)
New research has introduced Set-of-Mark (SoM), a new visual prompting method, to unleash extraordinary visual grounding abilities in large multimodal models (LMMs), such as GPT-4V.
As shown below, researchers employed off-the-shelf interactive segmentation models, such as SAM, to partition an image into regions at different levels of granularity and overlay these regions with a set of marks, e.g., alphanumerics, masks, boxes.

The experiments show that SoM significantly improves GPT-4V’s performance on complex visual tasks that require grounding.
Why does this matter?
In the past, a number of works attempted to enhance the abilities of LLMs by refining the way they are prompted or instructed. Thus far, prompting LMMs is rarely explored in academia. SoM represents a pioneering move in the domain and can help pave the road towards more capable LMMs.
That's all for now!
Stay tuned for more exciting research papers in pt.2!
If you are new to The AI Edge, subscribe now and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you tomorrow. 😊