


Microsoft ZeRO++: Unmatched Efficiency for LLM training
Plus: RepoFusion to train code models to understand your repository

Hello Engineering Leaders and AI Enthusiasts!
Welcome to the 49th edition of The AI Edge newsletter. This edition brings you ZeRO++ by Microsoft Research for high training efficiency of large models.
And a huge shoutout to our amazing readers. We appreciate you!😊
In today’s edition:
🚀 Microsoft ZeRO++: Unmatched efficiency for LLM training
🎯 RepoFusion: Training code models to understand your repository
📚 Knowledge Nugget: Understanding encoder and decoder LLMs by
Let’s go!
Microsoft ZeRO++: Unmatched efficiency for LLM training
Training large models requires considerable memory and computing resources across hundreds or thousands of GPU devices. Efficiently leveraging these resources requires a complex system of optimizations to:
1)Partition the models into pieces that fit into the memory of individual devices
2)Efficiently parallelize computing across these devices
But training on many GPUs results in small per-GPU batch size, requiring frequent communication and training on low-end clusters where cross-node network bandwidth is limited results in high communication latency.
To address these issues, Microsoft Research has introduced three communication volume reduction techniques, collectively called ZeRO++. It reduces total communication volume by 4x compared with ZeRO without impacting model quality, enabling better throughput even at scale.

Why does this matter?
ZeRO++ accelerates large model pre-training and fine-tuning, directly reducing training time and cost. Moreover, it makes efficient large model training accessible across a wider variety of clusters. It also improves the efficiency of workloads like RLHF used in training dialogue models.
RepoFusion: Training code models to understand your repository
LLMs for code have gained significant popularity, especially with integration into code assistants like GitHub Copilot 2. However, they often struggle to generalize effectively in unforeseen or unpredictable situations, resulting in undesirable predictions. Instances of such scenarios include code that uses private APIs or proprietary software, work-in-progress code, and any other context that the model has not seen while training.
To address these limitations, one possible approach is enhancing their predictions by incorporating the wider context available in the repository. This research proposes RepoFusion, a framework to train models to incorporate relevant repository context. Models trained with repository context significantly outperform several larger models despite being smaller in size.
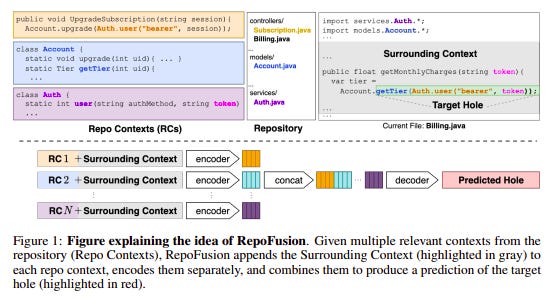
Why does this matter?
This will help code models make better predictions, enhancing the performance of developer assistance products and ones developed around them. It can also extend to other code-related tasks such as bug repair, the merging of pull requests, and software documentation/tutorial writing. Moreover, it opens up exciting avenues for future research LLMs for code.
Knowledge Nugget: Understanding encoder and decoder LLMs
In this insightful article,
explains the difference between encoder-style and decoder-style LLMs and how they work. The article discusses different architectures of Transformers and their applications, focusing on encoder-style, decoder-style, and encoder-decoder hybrids. It also clarifies the terminology and jargon used in the context of these models.Moreover, the article includes an overview of some of the most popular large language transformers organized by architecture type and developers.
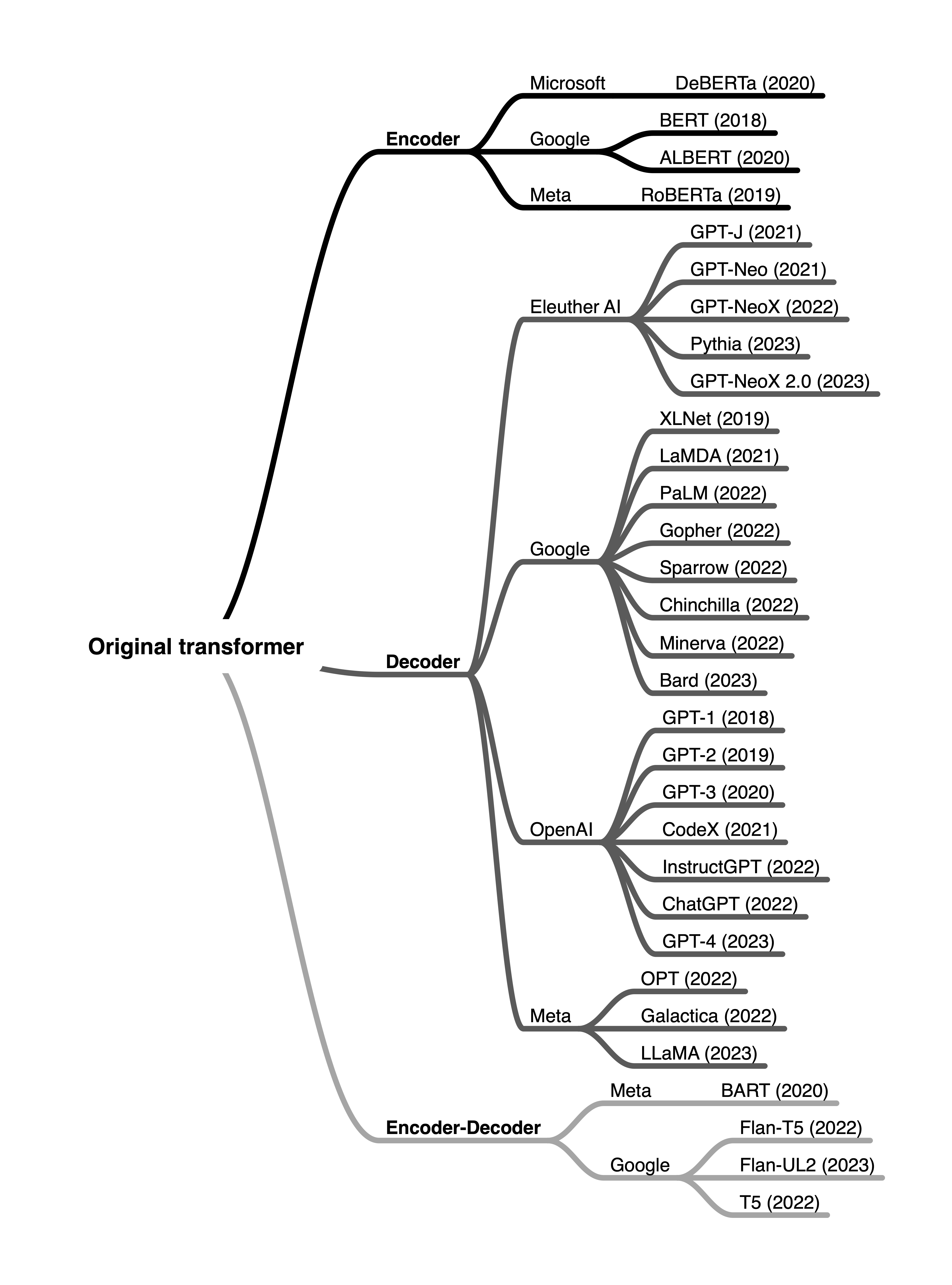
Why does this matter?
The article describes how different transformer architectures are apt for different use cases and helps shape the way AI systems are made. For instance, decoder-only models like GPT are popular for text generation tasks, while encoder-only models like BERT remain valuable for predictive models based on text embeddings.
What Else Is Happening❗

🔥Midjourney released an update in the Zoom Out feature, and people love it! (Link)
🔍LinkedIn’s new AI image detector spots fake profiles with 99% success rate (Link)
🚀Following the hype, the official code for DragGAN has been released! (Link)
🤗Whisper gets a new feature: word-level timestamps for word-level video trimming (Link)
💼LinkedIn’s upcoming feature will directly use generative AI in the share box (Link)
💡Archeologists will use AI to translate 5,000-year-old cuneiform tablets (Link)
🛠️ Trending Tools
EmbedAI: Create AI chatbots powered by ChatGPT using your data.
SatoshiGPT: Your ultimate AI companion for crypto journey. Learn, clarify doubts and stay updated.
Jarside: Generate quality texts at the best price using GPT technology and our own solutions.
Stockimg AI: Generate fantastic QR Codes designed by AI for free. No permission or attribution needed.
Barcode.so: Create beautiful and scannable QRCodes using generative AI that grab attention.
Investor Hunter: This AI-driven platform matches your startup with suitable investors and starts conversation.
PDF GPT: An AI-powered PDF assistant webapp. Process and analyze PDF documents effortlessly in your browser.
Makeayo: Create generative art from your PC with quality on par with Midjourney plus more creative control.
That's all for now!
If you are new to ‘The AI Edge’ newsletter. Subscribe to receive the ‘Ultimate AI tools and ChatGPT Prompt guide’ specifically designed for Engineering Leaders and AI enthusiasts.
Thanks for reading, and see you tomorrow!