
JPMorgan's DocLLM Understands Multimodal Data
Plus: Google DeepMind says image tweaks fool humans & AI, ByteDance introduces Diffusion Model.

Hello Engineering Leaders and AI Enthusiasts!
Welcome to the 180th edition of The AI Edge newsletter. This edition brings you JPMorgan’s New DocLLM for Multimodal Document Understanding.
And a huge shoutout to our incredible readers. We appreciate your support😊
In today’s edition:
🔍 JPMorgan announces DocLLM to understand multimodal docs
and 👏👏
🖼️ Google DeepMind says Image tweaks can fool humans and AI
📽️ ByteDance introduces the Diffusion Model with perceptual loss
📚 Knowledge Nugget: RAG vs. Context-Window in GPT-4: accuracy, cost, & latency by
Let’s go!
JPMorgan announces DocLLM to understand multimodal docs
DocLLM is a layout-aware generative language model designed to understand multimodal documents such as forms, invoices, and reports. It incorporates textual semantics and spatial layout information to effectively comprehend these documents. Unlike existing models, DocLLM avoids using expensive image encoders and instead focuses on bounding box information to capture the cross-alignment between text and spatial modalities.

It also uses a pre-training objective to learn to infill text segments, allowing it to handle irregular layouts and diverse content. The model outperforms state-of-the-art models on multiple document intelligence tasks and generalizes well to unseen datasets.
Why does this matter?
This new AI can revolutionize how businesses process documents like forms and invoices. End users will benefit from faster and more accurate document understanding. Competitors will need to invest heavily to match this technology. DocLLM pushes boundaries in multimodal AI - understanding both text and spatial layouts.
This could become the go-to model for document intelligence tasks, saving companies time and money. For example, insurance firms can automate claim assessments, while banks can speed loan processing.
Google DeepMind says Image tweaks can fool humans and AI
Google DeepMind’s new research shows that subtle changes made to digital images to confuse computer vision systems can also influence human perception. Adversarial images intentionally altered to mislead AI models can cause humans to make biased judgments.

The study found that even when more than 2 levels adjusted no pixel on a 0-255 scale, participants consistently chose the adversarial image that aligned with the targeted question. This discovery raises important questions for AI safety and security research and emphasizes the need for further understanding of technology's effects on both machines and humans.
Why does this matter?
AI vulnerabilities can unwittingly trick humans, too. Adversaries could exploit this to manipulate perceptions and decisions. It's a wake-up call for tech companies to enact safeguards and monitoring against AI exploitation.
ByteDance introduces the Diffusion Model with perceptual loss
This paper introduces a diffusion model with perceptual loss, which improves the quality of generated samples. Diffusion models trained with mean squared error loss often produce unrealistic samples. Current models use classifier-free guidance to enhance sample quality, but the reasons behind its effectiveness are not fully understood.

They propose a self-perceptual objective incorporating perceptual loss in diffusion training, resulting in more realistic samples. This method improves sample quality for conditional and unconditional generation without sacrificing sample diversity.
Why does this matter?
This advances diffusion models for more lifelike image generation. Users will benefit from higher-quality synthetic media for gaming and content creation applications. But it also raises ethical questions about deepfakes and misinformation.
Enjoying the daily updates?
Refer your pals to subscribe to our daily newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
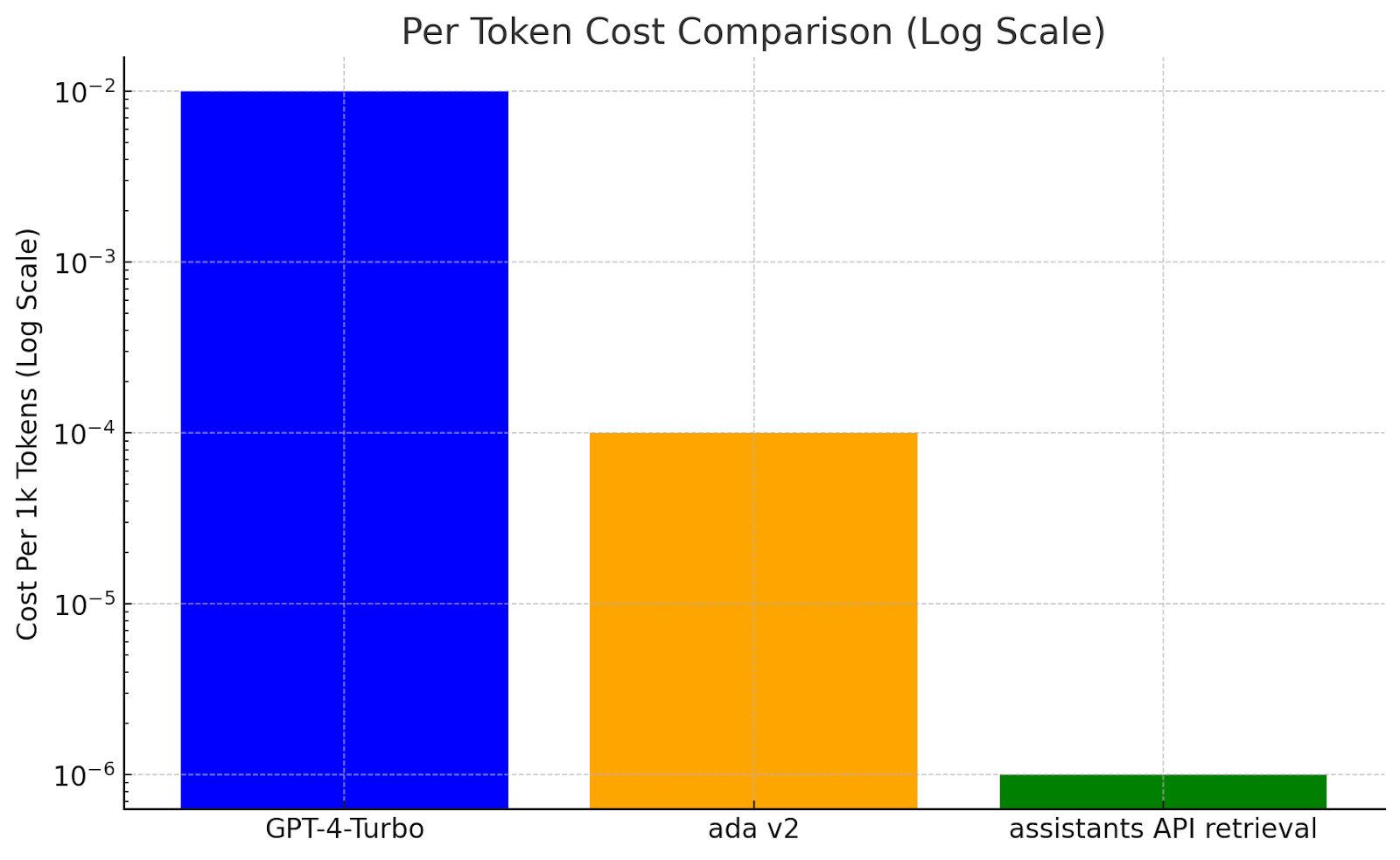
Knowledge Nugget: RAG vs. Context-Window in GPT-4: accuracy, cost, & latency
The authors
and compares the performance of RAG (Retrieval Augmented Generation) and context-window stuffing in GPT-4 in terms of accuracy, cost, and latency. They find that:RAG, when combined with GPT-4, delivers superior performance at only 4% of the cost.
RAG performs extremely well in accuracy, with near-perfect performance for search-style queries.
In terms of cost, RAG incurs a per-token cost as well as a fixed LLM reasoning cost, but it is significantly cheaper than context-window stuffing.
Latency is also competitive, with RAG showing lower end-to-end latencies than GPT-4.
Why does this matter?
This demonstrates RAG's potential to boost LLMs cost-effectively. Companies can integrate retrieve-and-generate capabilities to improve chatbots and search engines affordably. Cost-sensitive sectors like healthcare and education can implement capable AI assistants. Individual users also benefit from accurate, responsive AI across applications.
What Else Is Happening❗
🤖 Jellypipe launches AI for 3D printing, Optimizes material selection & pricing with GPT-4
It responds to customer queries and offers advice, including suggesting optimal materials for specific applications and creating dynamic price quotes. It is built on OpenAI's GPT-4 LLM system and has an internal materials database. Currently, it’s in beta testing. It will be launched to solution partners first and then to customers in general. (Link)
🚦 Seoul Govt (South Korea) plans to use drones and AI to monitor real-time traffic conditions by 2024
It will enhance traffic management and overall transportation efficiency. (Link)
🧠 Christopher Pissarides warns younger generations against studying STEM because AI could take over analytical tasks
He explains that the skills needed for AI advancements will become obsolete as AI takes over these tasks. Despite the high demand for STEM professionals, Pissarides argues that jobs requiring more traditional and personal skills will dominate the labor market in the long term. (Link)
👩🔬 New research from the University of Michigan found that LLMs perform better when prompted to act gender-neutral or male rather than female
This highlights the need to address biases in the training data that can lead machine learning models to develop unfair biases. The findings are a reminder to ensure AI systems treat all genders equally. (Link)
🤖 Samsung is set to unveil its new robot vacuum and mop combo
The robot vacuum uses AI to spot and steam-clean stains on hard floors. It also has the ability to remove its mops to tackle carpets. It features a self-emptying, self-cleaning charging base called the Clean Station, which refills the water tank and washes and dries the mop pads. (Link)

That's all for now!
If you are new to The AI Edge newsletter, subscribe to get daily AI updates and news directly sent to your inbox for free!
Thanks for reading, and see you tomorrow. 😊