


AI Weekly Rundown (May 27 to June 2)
News covering NVIDIA, OpenAI, Google, BiomedGPT, Break-A-Scene, Voyager, and more...

Hello, Engineering Leaders and AI Enthusiasts.
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
✅ NVIDIA uses AI to bring NPCs to life
✅ BiomedGPT: The most sophisticated AI medical model?
✅ Break-A-Scene: AI breaks down single image into multiple concepts
✅ Roop: 1 click AI face swap software with no dataset & training
✅ Voyager: First LLM lifelong learning agent that can continuously explore worlds
✅ LaVIN, for cheap and quick vision-language adaptation in LLMs
✅ Top AI scientists and experts sign statement urging safe AI
✅ Falcon topples LLaMA: Top open-source LM
✅ Open AI’s latest idea can help models do math with 78% accuracy
✅ Neuralangelo, NVIDIA’s new AI model, turns 2D video into 3D structures
✅ Google’s retrieval-augmented model addresses the challenge of pre-training
Let’s go
NVIDIA uses AI to bring NPCs to life
NVIDIA has announced the NVIDIA Avatar Cloud Engine (ACE) for Games. This cloud-based service provides developers access to various AI models, including natural language processing (NLP) models, facial animation models, and motion capture models.
ACE for Games can create NPCs that can have intelligent, unscripted, and dynamic conversations with players, express emotions, and realistically react to their surroundings.
It can help developers in many ways:
To create more realistic and believable NPCs with more natural and engaging conversations with players.
To save time and money by providing them access to various AI models.
BiomedGPT: The most sophisticated AI medical model?
BiomedGPT is a unified and generalist Biomedical Generative Pre-trained Transformer model. BiomedGPT utilizes self-supervision on diverse datasets to handle multi-modal inputs and perform various downstream tasks.

Extensive experiments show that BiomedGPT surpasses most previous state-of-the-art models in performance across 5 distinct tasks with 20 public datasets spanning over 15 biomedical modalities.
The study also demonstrates the effectiveness of the multi-modal and multi-task pretraining approach in transferring knowledge to previously unseen data.
Break-A-Scene: AI breaks down single image into multiple concepts
If given a photo of a ceramic artwork depicting a creature seated on a bowl, humans can effortlessly imagine the same creature in various poses and locations or envision the same bowl in a new setting. However, today's generative models struggle to do this type of task.
This research from Google (and others) introduces a new approach to textual scene decomposition. Given a single image of a scene that may contain multiple concepts of different kinds, it extracts a dedicated text token for each concept (handles) and enables fine-grained control over the generated scenes. The approach uses textual prompts in natural language for creating novel images featuring individual concepts or combinations of multiple concepts, as demonstrated in the video below.
Roop: 1 click AI face swap software with no dataset & training
Roop is a 1 click, deepfake face-swapping software. It allows you to replace the face in a video with the face of your choice. You only need one image of the desired face and that’s it- no dataset or training is needed.

In the future, they are aiming to:
Improve the quality of faces in results
Replace a selective face throughout the video
Support for replacing multiple faces

Voyager: First LLM lifelong learning agent that can continuously explore worlds
Voyager is the first LLM-powered lifelong learning agent in Minecraft that uses advanced learning techniques to explore, learn skills, and make discoveries without human input.
It consists of 3 key components:
Automatic curriculum for exploration.
Ever-growing skill library of executable code for storing and retrieving complex behaviors.
Iterative prompting mechanism for incorporating environment feedback, execution errors, & program improvement.

Voyager interacts with GPT-4 through blackbox queries, bypassing the need for fine-tuning. It demonstrates strong lifelong learning abilities and performs exceptionally well in Minecraft. Voyager rapidly becomes a seasoned explorer. In Minecraft, it obtains 3.3× more unique items, travels 2.3× longer distances, and unlocks key tech tree milestones up to 15.3× faster than prior methods & they have open-sourced everything!
LaVIN, for cheap and quick vision-language adaptation in LLMs
New research from Xiamen University has proposed a novel and cost-effective for adapting LLMs to vision-language (VL) instruction tuning called Mixture-of-Modality Adaptation (MMA).
MMA uses lightweight adapters, allowing joint optimization of an entire multimodal LLM with a small number of parameters. This saves more than thousand times of storage overhead compared with existing solutions. It can also obtain a quick shift between text-only and image-text instructions to preserve the NLP capability of LLMs.
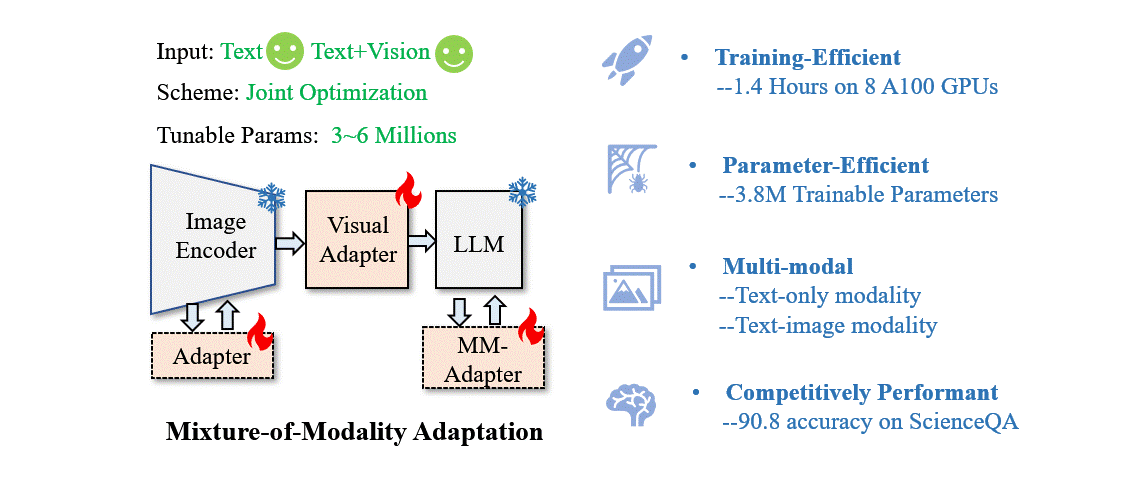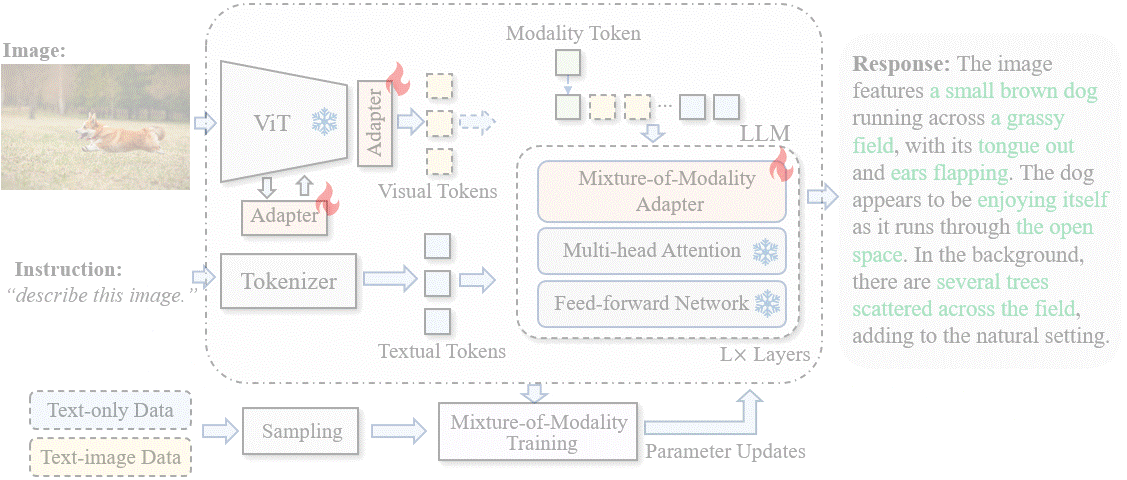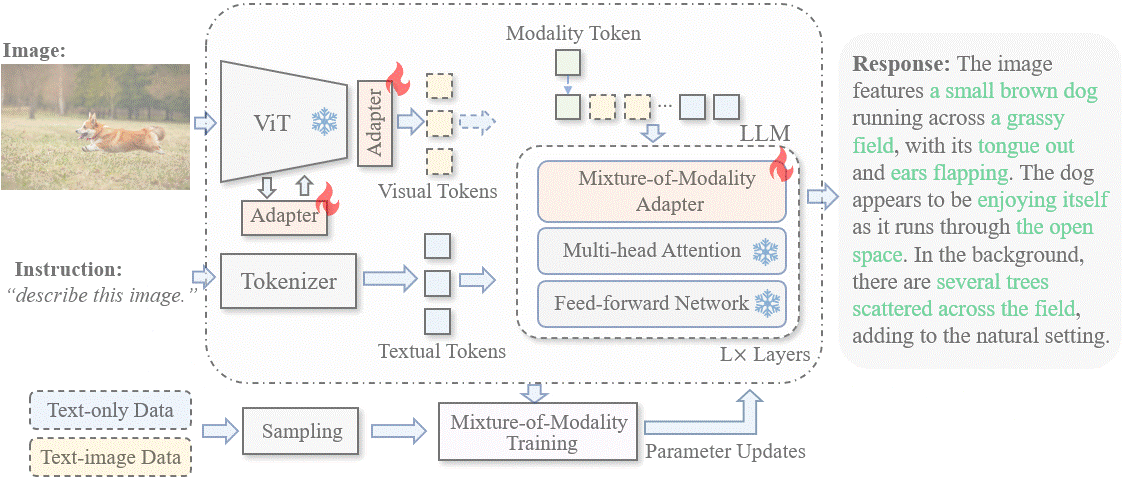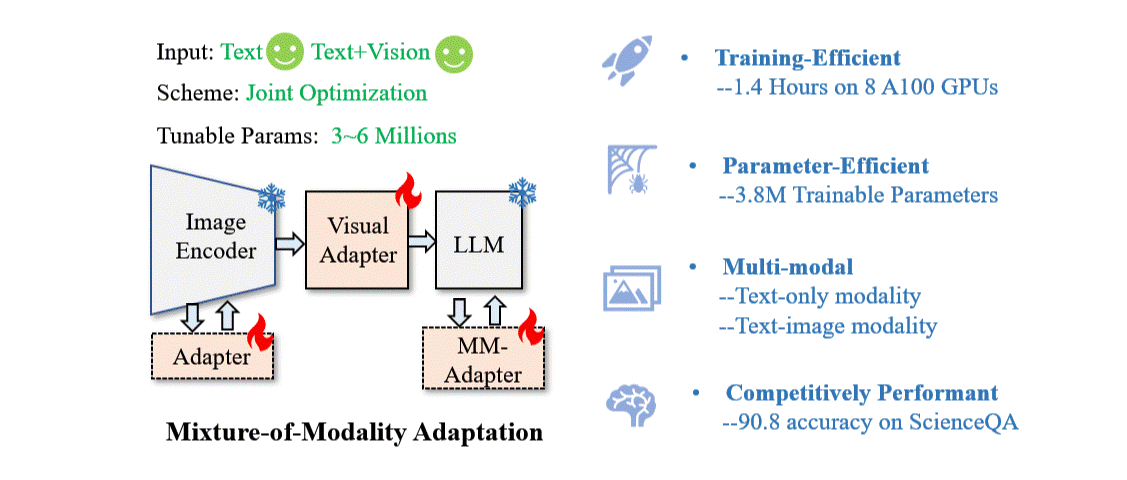
Based on MMA, a large vision-language instructed model called LaVIN was developed, enabling cheap and quick adaptations on VL tasks without requiring another large-scale pre-training. On conducting experiments on ScienceQA, LaVIN showed on-par performance with the advanced multimodal LLMs, with training time reduced by up to 71.4% and storage costs by 99.9%.
Top AI scientists and experts sign statement urging safe AI
In a bid to facilitate open discussions about the severe risks posed by advanced artificial intelligence (AI), a concise statement has been released, urging the global community to prioritize mitigating the risk of AI-induced extinction.

The statement highlights the importance of addressing this issue on par with other societal-scale risks like pandemics and nuclear war. The call has garnered support from a growing number of AI scientists and notable figures from various fields, including Sam Altman CEO-OpenAI, Dario Amodei CEO-Anthropic, Demis Hassabis CEO-Google DeepMind, and many more.
Falcon topples LLaMA: Top open-source LM
Falcon 40B, UAE’s leading large-scale open-source AI model from Technology Innovation Institute (TII), is now royalty-free for commercial and research use. Previously, it was released under a license requiring commercial royalty payments of 10%.
The model has been updated to Apache 2.0 software license, under which end-users have access to any patent covered by the software in question. TII has also provided access to the model’s weights to allow researchers and developers to use it to bring their innovative ideas to life.
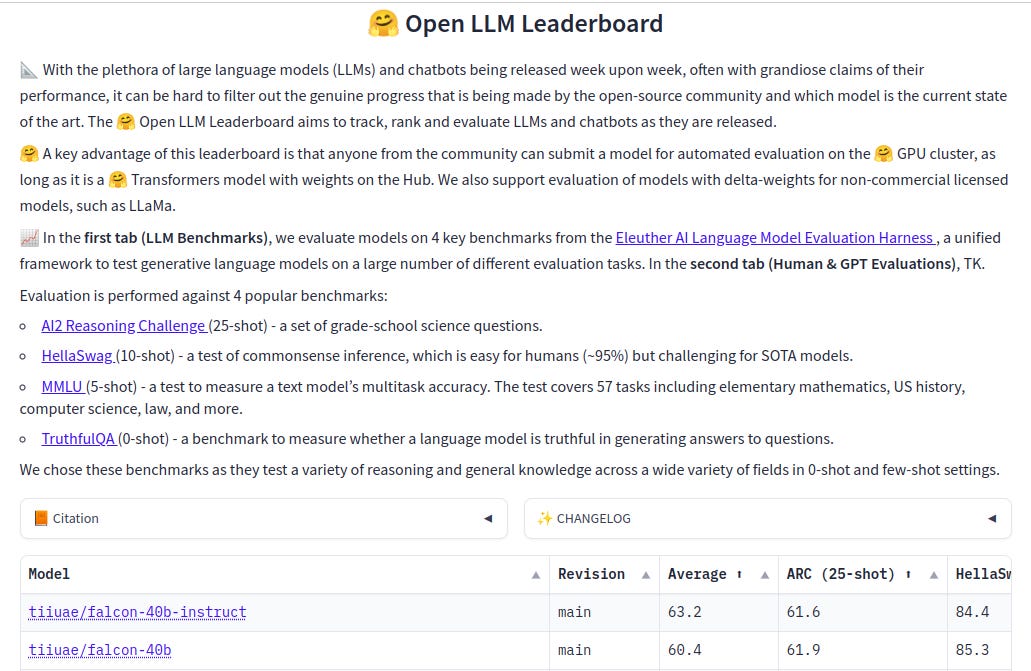
Ranked #1 globally on Hugging Face’s Open LLM leaderboard, Falcon 40B outperforms competitors like Meta’s LLaMA, Stability AI’s StableLM, and RedPajama from Together.
Open AI’s latest idea can help models do math with 78% accuracy
Even SoTA models today are prone to hallucinations, which can be particularly problematic in domains that require multi-step reasoning. To train more reliable models, OpenAI trained a model by rewarding each correct step of reasoning (“process supervision”) instead of simply rewarding the correct final answer (“outcome supervision”).
It was found that process supervision significantly outperforms outcome supervision for training models to solve problems from challenging MATH datasets. The model in the experiment solved 78% of problems from a representative subset of the MATH test set.

Additionally, process supervision also has an important alignment benefit: it directly trains the model to produce a chain-of-thought that is endorsed by humans.
Neuralangelo, NVIDIA’s new AI model, turns 2D video into 3D structures
NVIDIA Research has introduced a new AI model for 3D reconstruction called Neuralangelo. It uses neural networks to turn 2D video clips from any device– cell phone to drone capture– into detailed 3D structures, generating lifelike virtual replicas of buildings, sculptures, and other real-world objects.
Neuralangelo’s ability to translate the textures of complex materials — including roof shingles, panes of glass, and smooth marble — from 2D videos to 3D assets significantly surpasses prior methods. The high fidelity makes its 3D reconstructions easier for developers and creative professionals to rapidly create usable virtual objects for their projects using footage captured by smartphones.
Google’s retrieval-augmented model addresses the challenge of pre-training
Large-scale models like T5, GPT-3, PaLM, Flamingo, and PaLI have shown impressive knowledge storage abilities but require massive amounts of data and computational resources. Retrieval-augmented models in natural language processing (RETRO, REALM) and computer vision (KAT) aim to overcome these challenges by leveraging retrieval techniques. And researchers have attempted to address these challenges using retrieval-augmented models.

This model, “REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory,” can provide up-to-date information and improve efficiency by retrieving relevant information instead of relying solely on pre-training.
It learns to utilize a multi-source multi-modal “memory” to answer knowledge-intensive queries & allows the model parameters to focus on reasoning about the query rather than being dedicated to memorization.
That's all for now!
If you are new to ‘The AI Edge’ newsletter. Subscribe to receive the ‘Ultimate AI tools and ChatGPT Prompt guide’ specifically designed for Engineering Leaders and AI enthusiasts.
Thanks for reading, and see you Monday.