


AI Weekly Rundown (March 16 to March 22)
Major AI announcements from Google, NVIDIA, OpenAI, Microsoft, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
🕰️ 32-hour workweek with the same pay: AI’s new promise
🗣️ Google's VLOGGER brings photos to life as talking avatars
🔓 Elon Musk’s xAI open-sources Grok AI
💻 Nvidia launches 'world's most powerful AI chip'
🎥 Stability AI's SV3D turns a single photo into a 3D video
🤖 OpenAI CEO hints at "amazing model", maybe ChatGPT-5
🧠 MindEye2: AI Mind Reading from Brain Activity
🚀 Nvidia NIM enables faster deployment of AI models
🤝 Microsoft hires DeepMind co-founder to lead a new AI division
🕵️♂️ A new hack: Stealing Part of a Production Language Model
🧰 Sakana AI’s method to automate foundation model development
👋 Key Stable Diffusion researchers leave Stability AI
⏩ NVIDIA’s LATTE3D: The fastest AI model for 3D generation
📚 Language Models teach themselves to think before speaking
♟️ Neuralink's first human patient plays chess with his mind
Let’s go!
Bernie’s 4 day workweek: less work, same pay
Sen. Bernie Sanders has introduced the Thirty-Two Hour Workweek Act, which aims to establish a four-day workweek in the United States without reducing pay or benefits. To be phased in over four years, the bill would lower the overtime pay threshold from 40 to 32 hours, ensuring that workers receive 1.5 times their regular salary for work days longer than 8 hours and double their regular wage for work days longer than 12 hours.
Sanders, along with Sen. Laphonza Butler and Rep. Mark Takano, believes that this bill is crucial in ensuring that workers benefit from the massive increase in productivity driven by AI, automation, and new technology. The legislation aims to reduce stress levels and improve Americans' quality of life while also protecting their wages and benefits.
Google's AI brings photos to life as talking avatars
Google's latest AI research project VLOGGER, automatically generates realistic videos of talking and moving people from just a single image and an audio or text input. It is the first model that aims to create more natural interactions with virtual agents by including facial expressions, body movements, and gestures, going beyond simple lip-syncing.
It uses a two-step process: first, a diffusion-based network predicts body motion and facial expressions based on the audio, and then a novel architecture based on image diffusion models generates the final video while maintaining temporal consistency. VLOGGER outperforms previous state-of-the-art methods in terms of image quality, diversity, and the range of scenarios it can handle.
Elon Musk’s xAI open-sources Grok AI
Elon Musk's xAI has open-sourced the base model weights and architecture of its AI chatbot, Grok. This allows researchers and developers to freely use and build upon the 314 billion parameter Mixture-of-Experts model. Released under the Apache 2.0 license, the open-source version is not fine-tuned for any particular task.
This move aligns with Musk's criticism of companies that don't open-source their AI models, including OpenAI, which he is currently suing for allegedly breaching an agreement to remain open-source. While several fully open-source AI models are available, the most used ones are closed-source or offer limited open licenses.
Nvidia launches 'world's most powerful AI chip'
Nvidia has revealed its new Blackwell B200 GPU and GB200 "superchip", claiming it to be the world's most powerful chip for AI. Both B200 and GB200 are designed to offer powerful performance and significant efficiency gains.

Key takeaways:
The B200 offers up to 20 petaflops of FP4 horsepower, and Nvidia says it can reduce costs and energy consumption by up to 25 times over an H100.
The GB200 "superchip" can deliver 30X the performance for LLM inference workloads while also being more efficient.
Nvidia claims that just 2,000 Blackwell chips working together could train a GPT -4-like model comprising 1.8 trillion parameters in just 90 days.
Stability AI's SV3D turns a single photo into a 3D video
Stability AI released Stable Video 3D (SV3D), a new generative AI tool for rendering 3D videos. SV3D can create multi-view 3D models from a single image, allowing users to see an object from any angle. This technology is expected to be valuable in the gaming sector for creating 3D assets and in e-commerce for generating 360-degree product views.
SV3D builds upon Stability AI's previous Stable Video Diffusion model. Unlike prior methods, SV3D can generate consistent views from any given angle. It also optimizes 3D meshes directly from the novel views it produces.
SV3D comes in two variants: SV3D_u generates orbital videos from single images, and SV3D_p creates 3D videos along specified camera paths.
OpenAI CEO hints at "Amazing Model,” maybe ChatGPT-5
OpenAI CEO Sam Altman has announced that the company will release an "amazing model" in 2024, although the name has not been finalized. Altman also mentioned that OpenAI plans to release several other important projects before discussing GPT-5, one of which could be the Sora video model.
Altman declined to comment on the Q* project, which is rumored to be an AI breakthrough related to logic. He also expressed his opinion that GPT-4 Turbo and GPT-4 "kind of suck" and that the jump from GPT-4 to GPT-5 could be as significant as the improvement from GPT-3 to GPT-4.
MindEye2: AI mind reading from brain activity
MindEye2 is a revolutionary model that reconstructs visual perception from brain activity using just one hour of data. Traditional methods require extensive training data, making them impractical for real-world applications. However, MindEye2 overcomes this limitation by leveraging shared-subject models. The model is pretrained on data from seven subjects and then fine-tuned with minimal data from a new subject.

By mapping brain activity to a shared-subject latent space and then nonlinear mapping to CLIP image space, MindEye2 achieves high-quality reconstructions with limited training data. It performs state-of-the-art image retrieval and reconstruction across multiple subjects within only 2.5% of the previously required training data, reducing the training time from 40 to just one hour.
Nvidia NIM enables faster deployment of AI models
NVIDIA has introduced NVIDIA NIM (NVIDIA Inference Microservices) to accelerate the deployment of AI applications for businesses. NIM is a collection of microservices that package essential components of an AI application, including AI models, APIs, and libraries, into a container. These containers can be deployed in environments such as cloud platforms, Linux servers, or serverless architectures.

NIM significantly reduces the time it takes to deploy AI applications from weeks to minutes. It offers optimized inference engines, industry-standard APIs, and support for popular software and data platform vendors. NIM microservices are compatible with NVIDIA GPUs and support features like Retrieval Augmented Generation (RAG) capabilities for enhanced enterprise applications. Developers can experiment with NIM microservices for free on the ai.nvidia.com platform, while commercial deployment is available through NVIDIA AI Enterprise 5.0.
Microsoft hires DeepMind co-founder to lead a new AI division
Mustafa Suleyman, a renowned co-founder of DeepMind and Inflection, has recently joined Microsoft as the leader of Copilot. Satya Nadella, Microsoft's CEO, made this significant announcement, highlighting the importance of innovation in artificial intelligence (AI).
In his new role as the Executive Vice President and CEO of Microsoft AI, Mustafa will work alongside Karén Simonyan, another talented individual from Inflection who will serve as Chief Scientist. Together, they will spearhead the development and advancement of Copilot and other exciting consumer AI products at Microsoft. Mustafa and his team's addition to the Microsoft family brings a wealth of expertise and promises groundbreaking advancements in AI.
Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Stealing Part of a Production Language Model
Researchers from Google, OpenAI, and DeepMind (among others) released a new paper that introduces the first model-stealing attack that extracts precise, nontrivial information from black-box production language models like OpenAI’s ChatGPT or Google’s PaLM-2.
The attack allowed them to recover the complete embedding projection layer of a transformer language model. It differs from prior approaches that reconstruct a model in a bottom-up fashion, starting from the input layer. Instead, this operates top-down and directly extracts the model’s last layer by making targeted queries to a model’s API. This is useful for several reasons; it
Reveals the width of the transformer model, which is often correlated with its total parameter count.
Slightly reduces the degree to which the model is a complete “blackbox”
May reveal more global information about the model, such as relative size differences between different models
While there appear to be no immediate practical consequences of learning this layer is stolen, it represents the first time that any precise information about a deployed transformer model has been stolen.
Sakana AI’s method to automate foundation model development
Sakana AI has introduced Evolutionary Model Merge, a general method that uses evolutionary techniques to efficiently discover the best ways to combine different models from the vast ocean of different open-source models with diverse capabilities.
As of writing, Hugging Face has over 500k models in dozens of different modalities that, in principle, could be combined to form new models with new capabilities. By working with the vast collective intelligence of existing open models, this method is able to automatically create new foundation models with desired capabilities specified by the user.
Key Stable Diffusion researchers leave Stability AI
Robin Rombach and other key researchers who helped develop the Stable Diffusion text-to-image generation model have left the troubled, once-hot, now floundering GenAI startup.
Rombach (who led the team) and fellow researchers Andreas Blattmann and Dominik Lorenz were three of the five authors who developed the core Stable Diffusion research while at a German university. They were hired afterwards by Stability. Their departures are the latest in a mass exodus of executives at Stability AI, as its cash reserves dwindle and it struggles to raise additional funds.
Nvidia’s Latte 3D generates text-to-3D in seconds!
NVIDIA introduces Latte3D, facilitating the conversion of text prompts into detailed 3D models in less than a second. Developed by NVIDIA’s Toronto lab, Latte3D sets a new standard in generative AI models with its remarkable blend of speed and precision.
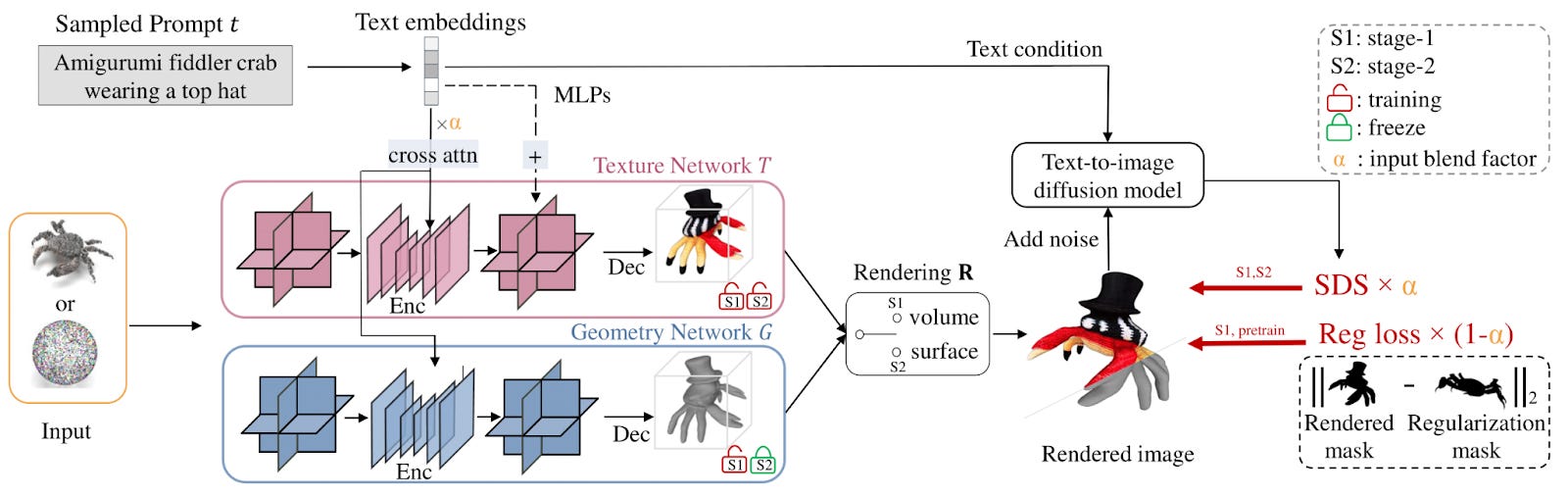
LATTE3D has two stages: first, NVIDIA’s team uses volumetric rendering to train the texture and geometry robustly, and second, it uses surface-based rendering to train only the texture for quality enhancement. Both stages use amortized optimization over prompts to maintain fast generation.

What sets Latte3D apart is its extensive pretraining phase, enabling the model to quickly adapt to new tasks by drawing on a vast repository of learned patterns and structures. This efficiency is achieved through a rigorous training regime that includes a blend of 3D datasets and prompts from ChatGPT.
Quiet-STaR: LMs can self-train to think before responding
A groundbreaking study demonstrates the successful training of large language models (LM) to reason from text rather than specific reasoning tasks. The research introduces a novel training approach, Quiet STaR, which utilizes a parallel sampling algorithm to generate rationales from all token positions in a given string.
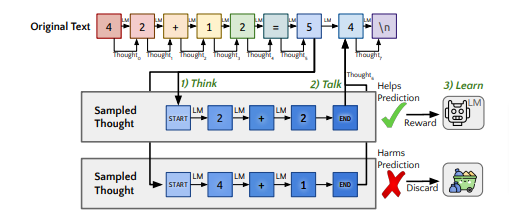
This technique integrates meta tokens to indicate when the LM should generate a rationale and when it should make a prediction based on the rationale, revolutionizing the understanding of LM behavior. Notably, the study shows that thinking enables the LM to predict difficult tokens more effectively, leading to improvements with longer thoughts.
The research introduces powerful advancements, such as a non-myopic loss approach, the application of a mixing head for retrospective determination, and the integration of meta tokens, underpinning a comprehensive leap forward in language model training.
Neuralink's first brain chip patient plays chess with his mind
Elon Musk's brain chip startup, Neuralink, showcased its first brain chip patient playing chess using only his mind. The patient, Noland Arbaugh, was paralyzed below the shoulder after a diving accident.
Neuralink's brain implant technology allows people with paralysis to control external devices using their thoughts. With further advancements, Neuralink's technology has the potential to revolutionize the lives of people with paralysis, providing them with newfound independence and the ability to interact with the world in previously unimaginable ways.
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊