


AI Weekly Rundown (June 15 to June 21)
Major AI announcements from NVIDIA, Meta, DeepMind, Anthropic, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
💻 NVIDIA's AI model for synthetic data generation rivals GPT-4
⚠️ Meta pauses AI model training in EU due to regulatory pushback
🎵 Spotify launches 'Creative Labs' to test Gen AI voiceover ads
🎬 Google DeepMind’s new AI can generate soundtracks for videos
🌟 Runway launches new model Gen-3 Alpha
🚀 China’s DeepSeek Coder V2 beats GPT-4 Turbo
🩺 OpenAI and Color Health join forces to accelerate cancer treatment
🎤 Meta unveils new AI models for audio, text, and watermarking
⚒️ Notion introduces AI Connectors for Slack & Google Drive integration
🖥️ Microsoft debuts a vision-foundational model for diverse tasks
👨💼 Ex-OpenAI co-founder launches own AI company
🧠 Can AI read minds? New model can predict anxiety levels
🤖 Anthropic’s Claude 3.5 is the world’s most intelligent model
🔬 PathChat: A new pathology-specific multimodal AI copilot
🔍 Not all ‘open source’ AI models are actually open: Here’s a ranking
Let’s go!
NVIDIA’s AI model for synthetic data generation rivals GPT-4
NVDIAI has released Nemotron-4 340B, an open-source pipeline for generating high-quality synthetic data. It includes a base model trained on 9M tokens, an instruction, and a reward model.
The instruction model can generate diverse synthetic data that mimics real-world data.
The reward model then evaluates the generated data to filter out high-quality responses.
This interaction between the two models produces better training data over time.
Note: 98% of the training data used to fine-tune the Instruct model is synthetic and was created using NVIDIA’s pipeline.

In benchmarks such as MT-Bench, MMLU, GSM8K, HumanEval, and IFEval, the Instruct model generally performs better than other open-source models such as Llama-3-70B-Instruct, Mixtral-8x22B-Instruct-v0.1, and Qwen-2-72B-Instruct, and in some tests, it even outperforms GPT-4o. This technical report provides detailed benchmarks.
Meta pauses AI model training in EU due to regulatory pushbacks
In response to the regulatory pressure from the Irish Data Protection Commission and the UK's Information Commissioner's Office, Meta has decided to pause its plans to train Llama using public content shared on Facebook and Instagram in the EU and the UK.
The regulators expressed concerns about Meta's plan to use this content without obtaining explicit user consent. Meta relied on a GDPR provision called "legitimate interests" to justify this data usage, but the regulators felt this was insufficient. Meta has decided to delay the launch of its AI chatbot in Europe until it can address the regulators' concerns and establish a more transparent user consent process.
Spotify launches ‘Creative Labs’ to test Gen AI voiceover ads
Spotify has launched a new in-house creative agency called “Creative Lab.” This agency will help brands and advertisers create custom campaigns for Spotify's platform. Creative Lab teams in different markets will provide local insights and collaborate with brands to develop campaigns through workshops, inspiration sessions, and collaborative ideation.
In addition, Spotify is also testing a new AI tool called "Quick Audio" that will allow brands to create scripts and voiceovers using generative AI technology. This new capability will be integrated into Spotify's ad manager platform, giving advertisers more options to produce audio ads for Spotify's audience of over 615 million listeners.
Google DeepMind’s new AI can generate soundtracks for videos
DeepMind is developing video-to-audio (V2A) technology to generate rich soundtracks for silent videos generated by AI models. V2A combines video pixels with natural language text prompts to create synchronized audiovisual content. The technology offers enhanced creative control, allowing users to guide the audio output using positive and negative prompts.
What sets DeepMind's V2A apart is its ability to understand raw pixels and generate audio without manual alignment. However, V2A struggles with artifacts or distortions in videos and generates audio that is not super convincing. As DeepMind continues to gather feedback from creators and filmmakers, they remain committed to developing this technology responsibly.
Runway launches new model Gen-3 Alpha
Runway launched Gen-3 Alpha, its latest AI model for generating video clips from text descriptions and still images. Gen-3 Alpha excels at generating expressive human characters with a wide range of actions, gestures, and emotions and can interpret various styles and cinematic terminology. However, it has limitations, including a maximum video length of 10 seconds, and struggles with complex character and object interactions and following the laws of physics precisely.
Runway partnered with entertainment and media organizations to create custom versions of Gen-3 for more stylistically controlled and consistent characters, targeting specific artistic and narrative requirements. They also have implemented safeguards, such as a moderation system to block attempts to generate videos from copyrighted images and a provenance system to identify videos coming from Gen-3.
China’s DeepSeek Coder V2 beats GPT-4 Turbo
Chinese AI startup DeepSeek has announced the release of DeepSeek Coder V2, an open-source code language model. It is built upon the DeepSeek-V2 MoE model and excels at coding and math tasks, supporting over 300 programming languages. It outperforms state-of-the-art closed-source models like GPT-4 Turbo, Claude 3 Opus, and Gemini 1.5 Pro, making it the first open-source model to achieve this feat. DeepSeek Coder V2 also maintains comparable performance in general reasoning and language capabilities.
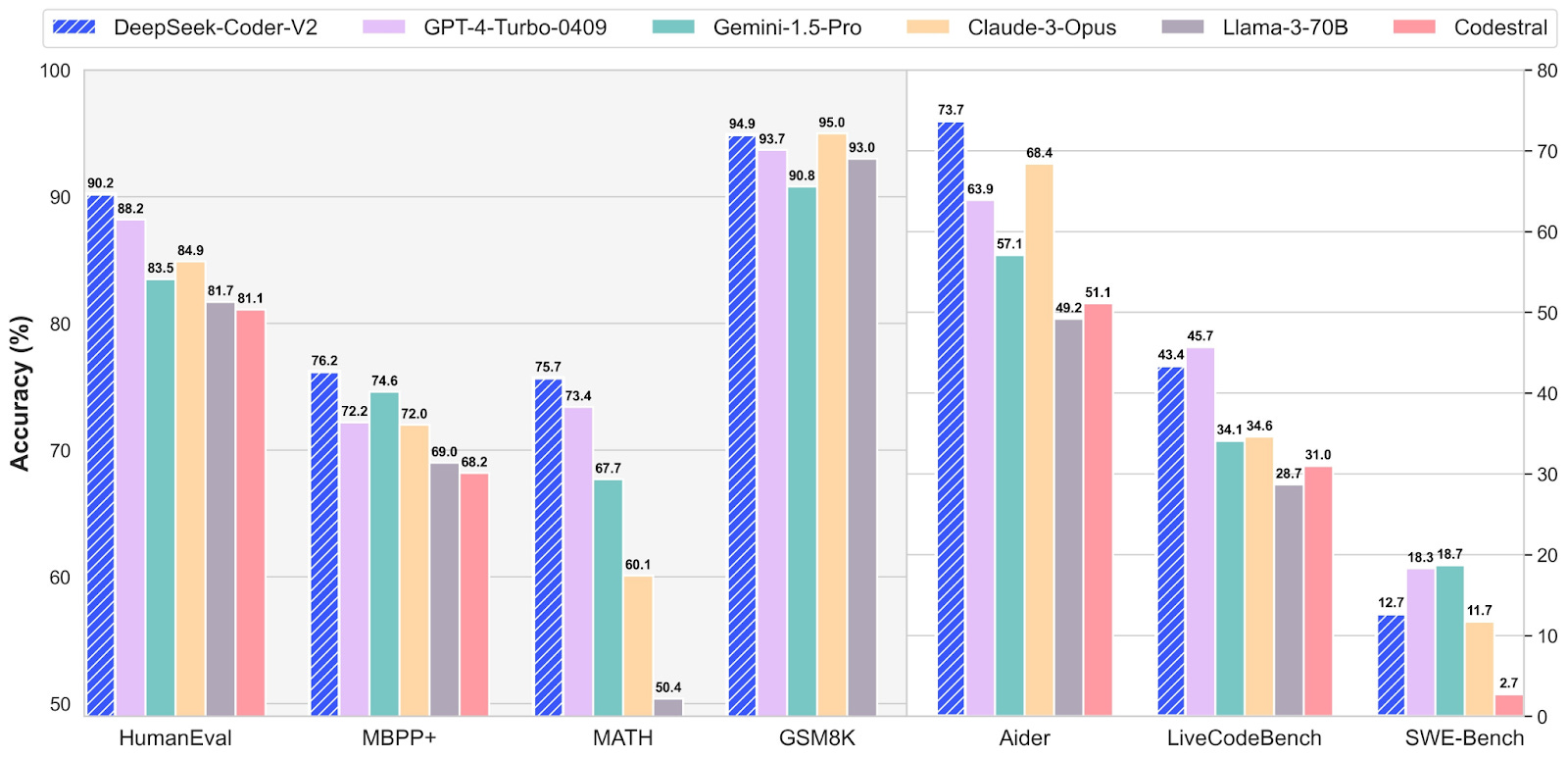
The model is being offered under an MIT license, which allows for research and unrestricted commercial use. It can be downloaded or accessed via API on DeepSeek's platform.
OpenAI and Color Health join forces to accelerate cancer treatment
In collaboration with OpenAI, Color Health has developed a copilot application that leverages OpenAI’s GPT-4o model to assist clinicians in accelerating cancer treatment.
The copilot integrates patient medical data with clinical knowledge using OpenAI’s APIs. Based on this data, the copilot generates customized, comprehensive treatment plans. These plans answer critical questions like “What screenings should the patient be doing?” and identify missing diagnostics.
A clinician evaluates the copilot’s output at each step. They can modify it if necessary before presenting it to the patient.
Meta unveils new AI models for audio, text, and watermarking
Meta’s Fundamental AI Research (FAIR) team has recently released several new AI models and tools for researchers to use. Here are the highlights:
JASCO: This AI model, short for “Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation,” allows users to adjust features of generated sound (such as chords, drums, and melodies) through text inputs. FAIR plans to release the JASCO inference code under an MIT license and the pre-trained model under a non-commercial Creative Commons license.
AudioSeal: This tool adds watermarks to AI-generated speech. It’s designed specifically for localized detection of AI-generated segments within longer audio snippets and will be released with a commercial license.
Chameleon: FAIR will release two sizes of its multimodal text model, Chameleon (7B and 34B), under a research-only license. These models can handle tasks requiring visual and textual understanding, such as image captioning.
Notion introduces AI Connectors for Slack & Google Drive integration
With AI Connectors, users can query Notion and receive responses from connected apps. The integration allows for selecting specific public channels or all public channels for information retrieval, excluding private channels and direct messages.
Notion AI can access up to a year of historical Slack content, which may take up to 36 hours. Additionally, users can set up various interactions between Notion and Slack, such as sending Slack messages to a Notion database, creating Notion tasks directly from Slack, and receiving notifications in Slack for specific events in Notion.
Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Microsoft debuts a vision-foundational model for diverse tasks
Florence 2, Microsoft’s vision-AI model, can perform diverse tasks like object detection, captioning, visual grounding, and visual question answering via image and text prompts. It displays excellent captioning, object detection, visual grounding, and segmentation.
The model comes in 232M and 771M parameter sizes and uses a sequence-to-sequence architecture, enabling multiple vision tasks without needing a task-specific architecture modification.
On fine-tuning the model with publicly available human-annotated data, Florence 2 showcased impressive results, offering tough competition to existing large vision models like Flamingo despite its compact size.
Ex-OpenAI co-founder launches own AI company
Just a month after leaving OpenAI, ex-cofounder Ilya Sutskever has launched his own AI company, Safe Superintelligence Inc. (SSI), alongside former Y Combinator partner Daniel Gross and ex-OpenAI engineer Daniel Levy as co-founders.
According to the SSI’s launch statement on X, the company will prioritize safety, progress, and security. Sutskever also emphasizes that the company’s “singular focus” on a joint approach to safety and capabilities will prevent it from being distracted by management overhead or production cycles, unlike companies like OpenAI or Google.

(Tweet Source)
Can AI read minds? New model can predict anxiety levels
Researchers at the University of Cincinnati have developed an AI model that can identify people with an urgent risk of anxiety. The AI model uses minimal computational resources, a short picture rating task, and a small set of variables to make the prediction. The approach named “Comp Cog AI” integrates computational cognition and AI.
Participants rated 48 pictures with mildly emotional subject matter based on the degree to which they liked or disliked those pictures. The response data was then used to quantify the mathematical features of their judgments. Finally, the data was combined with ML algorithms to identify their anxiety levels.
Since the technology doesn’t rely on a native language, it is accessible to a wider audience and diverse settings to assess anxiety.
Anthropic’s Claude 3.5 is the world’s most intelligent model
Anthropic is launching Claude 3.5 Sonnet, the first release in the forthcoming Claude 3.5 model family. Claude 3.5 Sonnet shows marked improvement in grasping nuance, humor, and complex instructions and is exceptional at writing high-quality content with a natural, relatable tone. It also operates at twice the speed of Claude 3 Opus and is Anthropic’s strongest vision model yet.
Claude 3.5 Sonnet is now available for free on Claude.ai and the Claude iOS app, while Claude Pro and Team plan subscribers can access it with significantly higher rate limits. It is also available via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI.
Anthropic is also introducing Artifacts on Claude.ai, a new feature that expands how users can interact with Claude.
PathChat: A new pathology-specific LLM
4 state-of-the-art LLMs were presented with an image of what looks like a mauve-colored rock. It’s actually a potentially serious tumor of the eye. When the models were asked about its location, origin, and possible extent,
LLaVA-Med identified it as the inner lining of the cheek
LLaVA said it is in the breast
GPT-4V offered a long, vague response, not identifying where it is at all
But PathChat, a new pathology-specific LLM, correctly pegs the tumor to the eye, informing that it can be significant and lead to vision loss. It is a multimodal generative AI copilot and chatbot for human pathology. It can serve as a consultant, of sorts, for human pathologists to help identify, assess, and diagnose tumors and other serious conditions.
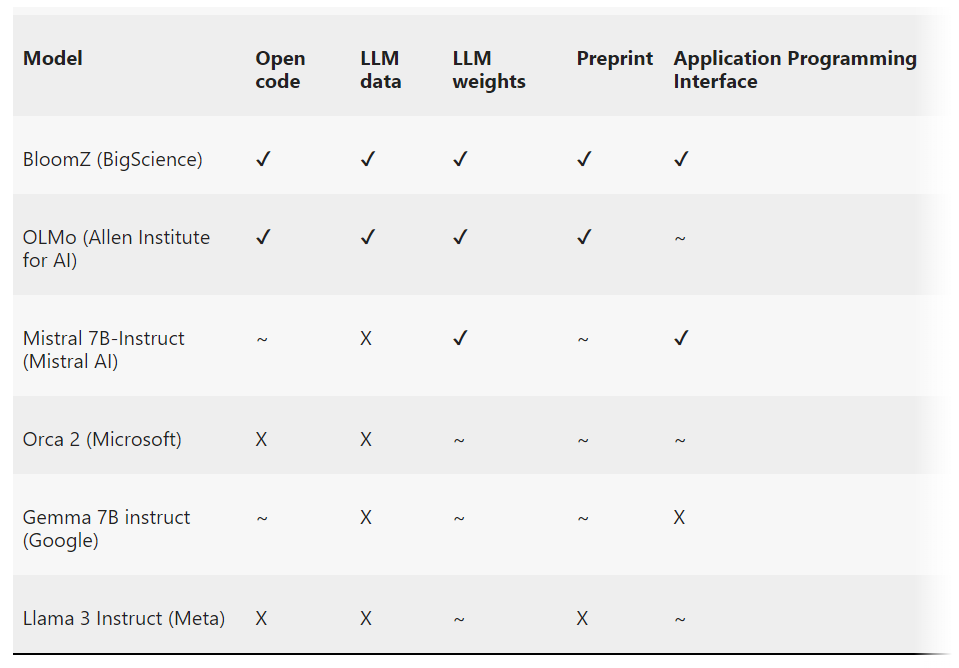
Not all ‘open source’ AI models are actually open: Here’s a ranking
Tech giants like Meta and Microsoft describe their AI models as ‘open source’ while failing to disclose important information about the underlying technology, say researchers who analyzed a host of popular chatbot models.
Access to code and training data is restricted, but these big firms reap the benefits of the claim and get away with disclosing as little as possible. This practice is known as open-washing. In fact, it's the smaller players who go the extra mile.
So, two language scientists created a league table identifying the most and least open models, assessing whether various components of chatbot models were open (✔), partially open (~), or closed (X).
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊