


AI Weekly Rundown (June 10 to June 16)
News from Meta, Google, Mind2Web, Hugging Face, and other major AI players.

Hello, Engineering Leaders and AI enthusiasts,
Another week with small but impactful AI developments. Here are the highlights from last week.
In today’s edition:
✅ Meta’s MusicGen: The LLaMA moment for music AI
✅ Google’s Imagen Editor outperforms Stable Diffusion and DALL-E 2
✅ Mind2Web: AI automates your tedious web tasks
✅ Hugging Face Transformers v4.30 gets impressive new features
✅ Meta’s new human-like AI model for image creation
✅ Google’s human attention models can enhance UX
✅ Google AI Lets You Step into 3D Indoors
✅ Rerender A Video: Zero-shot text-guided video-to-video AI
✅ Google’s 12sec inference latency sets a new benchmark
✅ Hugging Face introduces QR code AI art generator
Let’s go!
Meta’s MusicGen: The LLaMA moment for music AI
META released MusicGen, a controllable music generation model for producing high-quality music. MusicGen can be prompted by both text and melody.
The best thing is anyone can try it for free now. It uses a single-stage transformer language model with efficient token interleaving patterns, eliminating the need for multiple models.

MusicGen will generate 12 seconds of audio based on the description provided. You can optionally provide a reference audio from which a broad melody will be extracted. Then the model will try to follow both the description and melody provided. You can also use your own GPU or a Google Colab by following the instructions on their repo.
📃 Paper: https://arxiv.org/abs/2306.05284
💻 GitHub: https://github.com/facebookresearch/audiocraft
🎧 Try it here: https://huggingface.co/spaces/facebook/MusicGen
Google’s Imagen Editor outperforms Stable Diffusion and DALL-E 2
Despite the explosion of breakthroughs in text-to-image AI, text-guided image editing (TGIE) is a convenient solution when recreating visuals would be time-consuming or infeasible. Google has introduced Imagen Editor, a SoTA solution for text-guided image inpainting fine-tuned from Imagen.
It takes three inputs from the user: 1) the image to be edited, 2) a binary mask to specify the edit region, and 3) a text prompt — all three inputs guide the output samples. The model meaningfully incorporates the user’s intent and performs photorealistic edits.

Google also introduced EditBench, a method that gauges the quality of image editing models. It drills down to various types of attributes, objects, and scenes for a more fine-grained understanding of performance.
When evaluated against Stable Diffusion (SD) and DALL-E 2 (DL2), Imagen Editor outperforms them by substantial margins across all EditBench evaluation categories.
Mind2Web: AI automates your tedious web tasks
Mind2Web is a newly introduced dataset aimed at developing and evaluating generalist agents for the web. It provides a diverse range of over 2,000 open-ended tasks collected from 137 real-world websites across 31 domains. The dataset includes crowdsourced action sequences for these tasks, making it suitable for training agents that can follow language instructions to complete complex tasks on any website.

Unlike existing datasets, Mind2Web focuses on real-world websites rather than simulated ones, offering a broad spectrum of user interaction patterns. Researchers have explored using LLMs for building generalist web agents using Mind2Web, demonstrating decent performance even on unseen websites.
Hugging Face Transformers v4.30 gets impressive new features
The latest version of Hugging Face Transformers (v4.30) includes some impressive new features:
4-bit quantization, which allows you to run LLMs on much smaller devices. You can now run a 30B model on an off-the-shelf 24GB GPU.
Support for conditional image-to-text generation with the pipeline. You can use it to steer the generation in a certain direction or for visual question answering (VQA).
You can now run agents locally– the control is yours, no dependencies on external APIs.
Safetensors as a core dependency. Safetensors' security has been audited by an external company and will become the default serialization solution, regardless of the ML framework.
Speech recognition from 1000+ languages. Meta's MMS has been incorporated into 🤗 transformers, allowing you to handle language diversity.
Meta’s new human-like AI model for image creation
Meta has introduced a new model, Image Joint Embedding Predictive Architecture (I-JEPA), based on Meta’s Chief AI Scientist Yann LeCun’s vision to make AI systems learn and reason like animals and humans. It is a self-supervised computer vision model that learns to understand the world by predicting it.
The core idea: It learns by creating an internal model of the outside world and comparing abstract representations of images. It uses background knowledge about the world to fill in missing pieces of images, rather than looking only at nearby pixels like other generative AI models.
Key takeaways: The model
Captures patterns and structures through self-supervised learning from unlabeled data.
Predicts missing information at a high level of abstraction, avoiding generative model limitations.
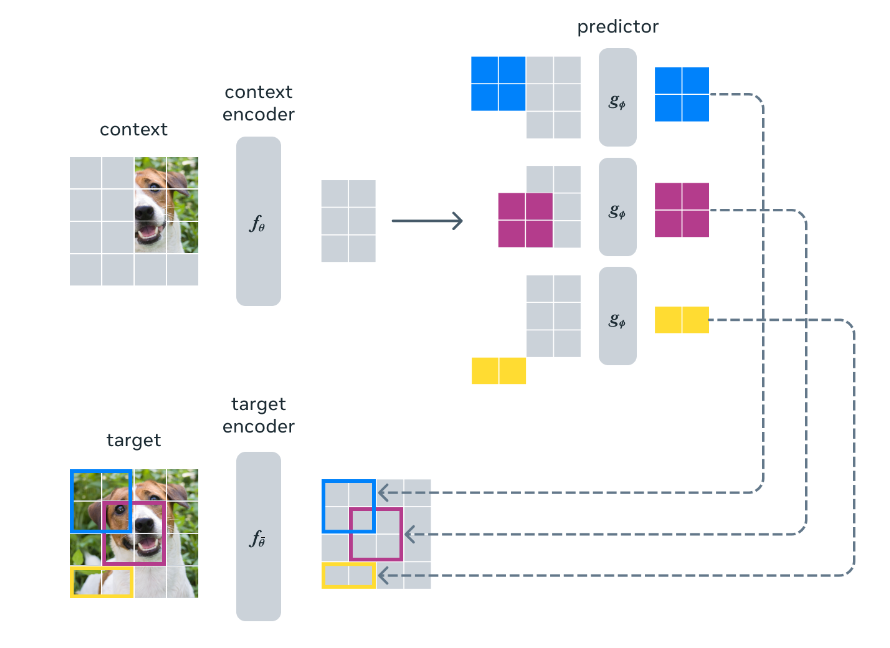
Delivers strong performance on multiple computer vision tasks while also being computationally efficient. Less data, less time, and less compute.
Can be used for many different applications without needing extensive fine-tuning and is highly scalable.
Google’s human attention models can enhance UX
Google presents new research in the area of human attention modeling. It showcases how predictive models of human attention can enhance user experiences, such as image editing to minimize visual clutter, distraction or artifacts, and image compression for faster loading of webpages or apps.
Attention-guided image editing: Human attention models usually take an image as input and predict a heatmap as output. The heatmap is evaluated against ground-truth attention data, typically collected by an eye tracker or approximated via mouse hovering/clicking. Edits based on the heatmap can significantly change an observer’s attention to different image regions. For example, reducing clutter in the background in video conferencing may increase focus on the main speaker.

Google AI Lets You Step into 3D Indoors
Google reveals how it uses neural radiance fields (NeRF) in Immersive View to seamlessly fuse photos to produce realistic, multi-dimensional reconstructions within a neural network. Immersive View in Google Maps provides indoor views of restaurants, cafes, and other venues in 3D to give users a virtual up-close look that can help them confidently decide where to go.

Google describes its complete pipeline, from capturing photos of the space using DSLR cameras to enabling the 3D interactive 360° videos to be available on smartphones.
Rerender A Video: Zero-shot text-guided video-to-video AI
New research has proposed a novel zero-shot text-guided video-to-video translation framework to adapt image models to videos. Called Rerender A Video, it takes an input video and re-renders it with your text prompt. It achieves both global and local temporal consistency at a low cost (without re-training or optimization).

Moreover, it is compatible with existing image diffusion techniques, indicating that it might be applied to other text-guided video editing tasks, such as video super-resolution and inpainting.
Google’s 12sec inference latency sets a new benchmark
Researchers have developed a series of implementation optimizations for large diffusion models used in artificial intelligence. These optimizations enable the fastest reported inference latency on GPU-equipped mobile devices, enhancing the user experience and expanding the applicability of generative AI.
The improvements address challenges posed by these models' size and resource requirements, allowing for on-device deployment with benefits such as lower server costs and improved privacy. The Samsung S23 Ultra achieved impressive results, with inference latency under 12 seconds for a 512x512 image and 20 iterations of the Stable Diffusion 1.4 model without int8 quantization.
(Stable Diffusion runs on modern smartphones in under 12 seconds. Note that running the decoder after each iteration for displaying the intermediate output in this animated GIF results in a ~2× slowdown.)
Paper: https://arxiv.org/pdf/2304.11267.pdf
Hugging Face introduces QR code AI art generator
The Hugging Face hub now has the first QR code AI art generator. All you need is the QR code content and a text-to-image prompt idea, or you can upload your image. And it will generate a QR code-based artwork that is aesthetically pleasing while still maintaining the integral QR code shape.
That's all for now!
If you are new to ‘The AI Edge’ newsletter. Subscribe to receive the ‘Ultimate AI tools and ChatGPT Prompt guide’ specifically designed for Engineering Leaders and AI enthusiasts.
Thanks for reading, and see you Monday.