


AI Weekly Rundown (July 13 to July 19)
Major AI announcements from OpenAI, Meta, Mistral, YouTube, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
🍓 OpenAI is working on an AI codenamed "Strawberry"
🧠 Meta researchers developed "System 2 distillation" for LLMs
🛒 Amazon's Rufus AI is now available in the US
💻 AMD amps up AI PCs with next-gen laptop chips
🎵 YT Music tests AI-generated radio, rolls out sound search
🤖 3 mysterious AI models appear in the LMSYS arena
📅 Meta’s Llama 3 400B drops next week
🚀 Mistral AI adds two new models to its growing family of LLMs
⚡ FlashAttention-3 enhances computation power of NVIDIA GPUs
🏆 DeepL’s new LLM crushes GPT-4, Google, and Microsoft
🆕 Salesforce debuts Einstein service agent
👨🏫 Ex-OpenAI researcher launches AI education company
🔍 OpenAI introduces GPT-4o mini, its most affordable model
🤝 Mistral AI and NVIDIA collaborate to release a new model
🌐 TTT models might be the next frontier in generative AI
Let’s go!
OpenAI is working on an AI codenamed "Strawberry"
The project aims to improve AI's reasoning capabilities. It could enable AI to navigate the internet on its own, conduct "deep research," and even tackle complex, long-term tasks that require planning ahead.
The key innovation is a specialized post-training process for AI models. The company is creating, training, and evaluating models on a "deep-research" dataset. The details about how previously known as Project Q, Strawberry works are tightly guarded, even within OpenAI.
The company plans to test Strawberry's capabilities in conducting research by having it browse the web autonomously and perform tasks normally performed by software and machine learning engineers.
Meta researchers developed "System 2 distillation" for LLMs
Meta researchers have developed a "System 2 distillation" technique that teaches LLMs to tackle complex reasoning tasks without intermediate steps. This breakthrough could make AI applications zippier and less resource-hungry.
This new method, inspired by how humans transition from deliberate to intuitive thinking, showed impressive results in various reasoning tasks. However, some tasks, like complex math reasoning, could not be successfully distilled, suggesting some tasks may always require deliberate reasoning.
Amazon's Rufus AI is now available in the US
Amazon's AI shopping assistant, Rufus is now available to all U.S. customers in the Amazon Shopping app.
Key capabilities of Rufus include:
Answers specific product questions based on product details, customer reviews, and community Q&As
Provides product recommendations based on customer needs and preferences
Compares different product options
Keeps customers updated on the latest product trends
Accesses current and past order information
This AI assistant can also tackle broader queries like "What do I need for a summer party?" or "How do I make a soufflé?" – proving it's not just a product finder but a full-fledged shopping companion.
Amazon acknowledges that generative AI and Rufus are still in their early stages, and they plan to continue improving the assistant based on customer feedback and usage.
AMD amps up AI PCs with next-gen laptop chips
AMD has revealed details about its latest architecture for AI PC chips. The company has developed a new neural processing unit (NPU) integrated into its latest AMD Ryzen AI processors. This NPU can perform AI-related calculations faster and more efficiently than a standard CPU or integrated GPU.
These chips' new XDNA 2 architecture provides industry-leading performance for AI workloads. The NPU can deliver 50 TOPS (trillion operations per second) of performance, which exceeds the capabilities of competing chips from Intel, Apple, and Qualcomm. AMD is touting these new AI-focused PC chips as enabling transformative experiences in collaboration, content creation, personal assistance, and gaming.

YT Music tests AI-generated radio, rolls out sound search
YouTube Music is introducing two new features to help users discover new music.
An AI-generated "conversational radio" feature that allows users to create a custom radio station by describing the type of music they want to hear. This feature is rolling out to some Premium users in the US.
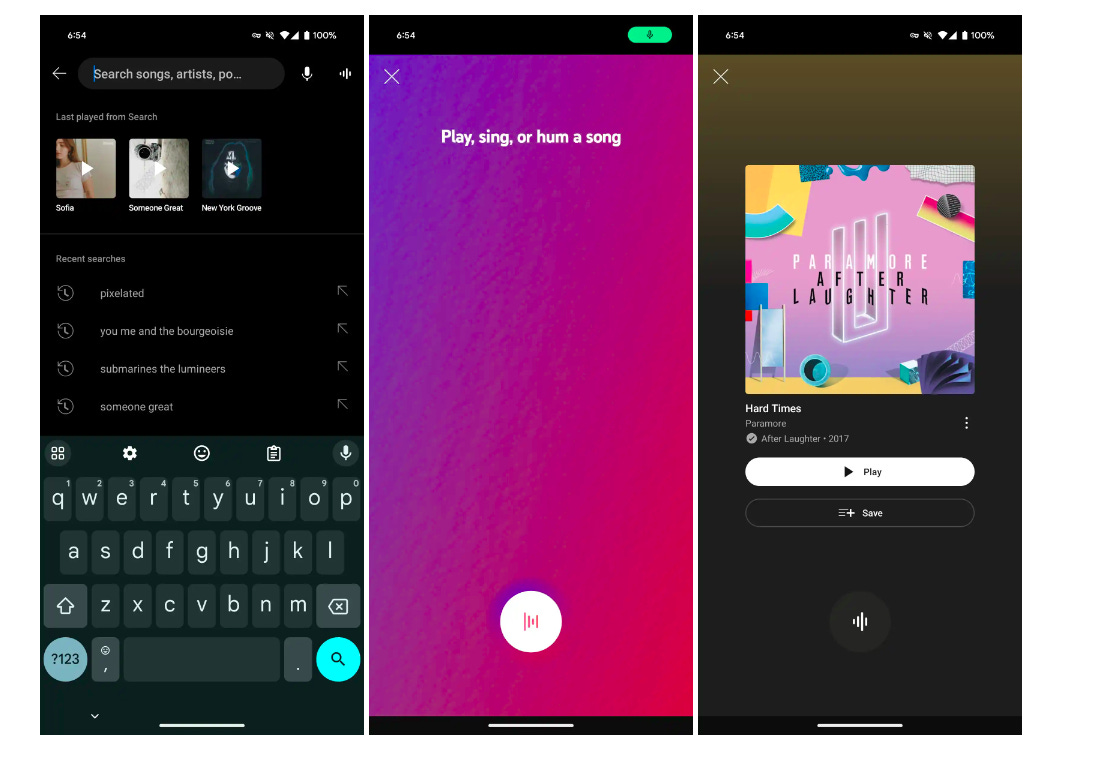
A new song recognition feature that lets users search the app's catalog by singing, humming, or playing parts of a song. It is similar to Shazam but allows users to find songs by singing or humming, not just playing the song. This feature is rolling out to all YouTube Music users on iOS and Android.
3 mysterious AI models appear in the LMSYS arena
Three mysterious new AI models have appeared in the LMSYS Chatbot Arena for testing. These models are 'upcoming-gpt-mini,' 'column-u,' and 'column-r.' The 'upcoming-gpt-mini' model identifies itself as ChatGPT and lists OpenAI as the creator, while the other two models refuse to reveal any identifying details.
The new models are available in the LMSYS Chatbot Arena’s ‘battle’ section, which puts anonymous models against each other to gauge outputs via user vote.
Meta’s Llama 3 400B drops next week
Meta plans to release the largest version of its open-source Llama 3 model on July 23, 2024. It boasts over 400 billion parameters and multimodal capabilities.
It is particularly exciting as it performs on par with OpenAI's GPT-4o model on the MMLU benchmark despite using less than half the parameters. Another compelling aspect is its open license for research and commercial use.
Mistral AI adds 2 new models to its growing family of LLMs
Mistral launched Mathstral 7B, an AI model designed specifically for math-related reasoning and scientific discovery. It has a 32k context window and is published under the Apache 2.0 license.

(Source)
Mistral also launched Codestral Mamba, a Mamba2 language model specialized in code generation, available under an Apache 2.0 license. Mistral AI expects it to be a great local code assistant after testing it on in-context retrieval capabilities up to 256k tokens.
(Source)
FlashAttention-3 enhances computation power of NVIDIA GPUs
Researchers from Colfax Research, Meta, Nvidia, Georgia Tech, Princeton University, and Together AI have introduced FlashAttention-3, a new technique that significantly speeds up attention computation on Nvidia Hopper GPUs (H100 and H800).
Attention is a core component of the transformer architecture used in LLMs. But as LLMs grow larger and handle longer input sequences, the computational cost of attention becomes a bottleneck.
FlashAttention-3 takes advantage of new features in Nvidia Hopper GPUs to maximize performance. It achieves up to 75% usage of the H100 GPU’s maximum capabilities.
Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
DeepL’s new LLM crushes GPT-4, Google, and Microsoft
The next-generational language model for DeepL translator specializes in translating and editing texts. Blind tests showed that language professionals preferred its natural translations 1.3 times more often than Google Translate and 1.7 times more often than ChatGPT-4.
Here’s what makes it stand out:
While Google’s translations need 2x edits, and ChatGPT-4 needs 3x more edits, DeepL’s new LLM requires much fewer edits to achieve the same translation quality, efficiently outperforming other models.
The model uses DeepL’s proprietary training data, specifically fine-tuned for translation and content generation.
To train the model, a combination of AI expertise, language specialists, and high-quality linguistic data is used, which helps it produce more human-like translations and reduces hallucinations and miscommunication.
Salesforce debuts Einstein service agent
The new Einstein service agent offers customers a conversational AI interface, takes actions on their behalf, and integrates with existing customer data and workflows.
The Einstein 1 platform's service AI agent offers diverse capabilities, including autonomous customer service, generative AI responses, and multi-channel availability. It processes various inputs, enables quick setup, and provides customization while ensuring data protection.
Salesforce demonstrated the AI's abilities through a simulated interaction with Pacifica AI Assistant. The AI helped a customer troubleshoot an air fryer issue, showcasing its practical problem-solving skills in customer service scenarios.
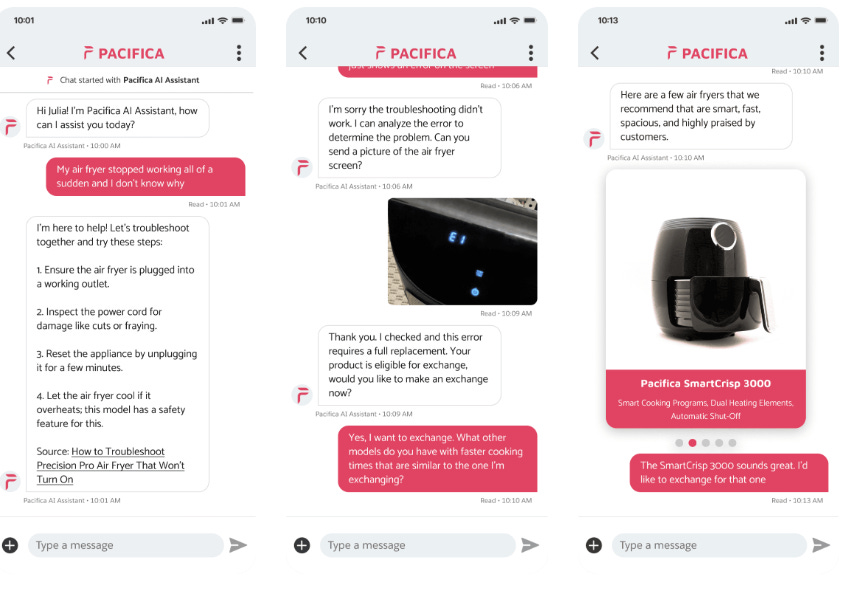
(Source)
Ex-OpenAI researcher launches AI education company
In a Twitter post, ex-Tesla director and former OpenAI co-founder Andrej Karpathy announced the launch of EurekaLabs, an AI+ education startup.
EurekaLabs will be a native AI company using generative AI as a core part of its platform. The startup shall build on-demand AI teaching assistants for students by expanding on course materials designed by human teachers.
Karpathy states that the company’s first product would be an undergraduate-level class, empowering students to train their own AI systems modeled after EurekaLabs’ teaching assistant.
OpenAI introduces GPT-4o mini, its most affordable model
OpenAI has introduced GPT-4o mini, its most intelligent, cost-efficient small model. It supports text and vision in the API, with support for text, image, video and audio inputs and outputs coming in the future. The model has a context window of 128K tokens, supports up to 16K output tokens per request, and has knowledge up to October 2023.
GPT-4o mini scores 82% on MMLU and currently outperforms GPT-4 on chat preferences in the LMSYS leaderboard. It is more affordable than previous frontier models and more than 60% cheaper than GPT-3.5 Turbo.

Mistral AI and NVIDIA collaborate to release a new model
Mistral releases Mistral NeMo, its new best small model with a large context window of up to 128k tokens. It was built in collaboration with NVIDIA and released under the Apache 2.0 license.

Its reasoning, world knowledge, and coding accuracy are state-of-the-art in its size category. Relying on standard architecture, Mistral NeMo is easy to use and a drop-in replacement for any system using Mistral 7B. It is also on function calling and is particularly strong in English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi.
TTT models might be the next frontier in generative AI
Transformers have long been the dominant architecture for AI, powering OpenAI’s Sora, GPT-4o, Claude, and Gemini. But they aren’t especially efficient at processing and analyzing vast amounts of data, at least on off-the-shelf hardware.
Researchers at Stanford, UC San Diego, UC Berkeley, and Meta proposed a promising new architecture this month. The team claims that Test-Time Training (TTT) models can not only process far more data than transformers but that they can do so without consuming nearly as much compute power. Here is the full research paper.
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊