


AI Weekly Rundown (February 10 to February 16)
Major AI announcements from Google, OpenAI, Meta, Cohere, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
📊 DeepSeekMath: The key to mathematical LLMs
💻 localllm enables GenAI app development without GPUs
📱 IBM researchers show how GenAI can tamper calls
🔍 More Agents = More Performance: Tencent Research
🎥 Google DeepMind’s MC-ViT understands long-context video
🎙 ElevenLabs lets you turn your voice into passive income💻 Nvidia launches offline AI chatbot trainable on local data
🧠 ChatGPT can now remember conversations
🌐 Cohere launches open-source LLM in 101 languages🎥 Apple’s Keyframer: A text-to-anime AI using GPT-4
🖼️ Stability AI introduced Stable Cascade: A text-to-image model
🛡️ OpenAI disrupted the activities of 5 state-affiliated threat actors🚀 OpenAI launches Sora, a text-to-video model
🌟 Google announces Gemini 1.5 with 1 million tokens!
🤖 Meta’s V-JEPA: A step toward advanced machine intelligence
Let’s go!
DeepSeekMath: The key to mathematical LLMs
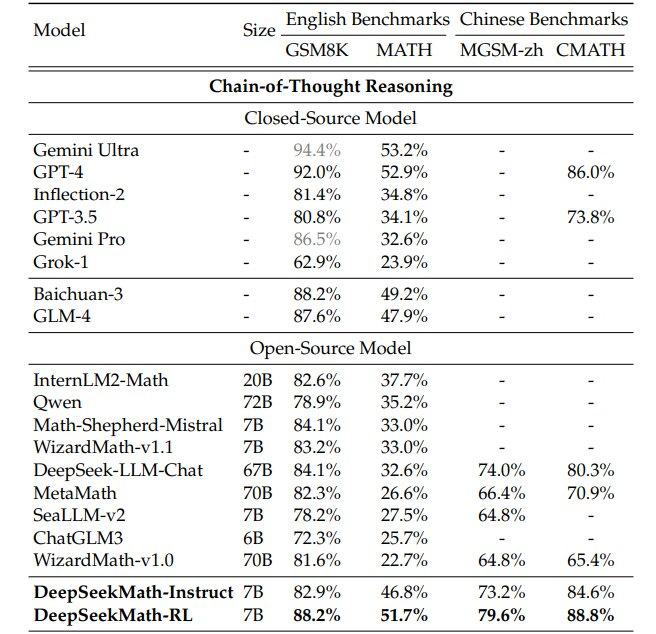
In its latest research paper, DeepSeek AI has introduced a new AI model, DeepSeekMath 7B, specialized for improving mathematical reasoning in open-source LLMs. It has been pre-trained on a massive corpus of 120 billion tokens extracted from math-related web content, combined with reinforcement learning techniques tailored for math problems.
When evaluated across crucial English and Chinese benchmarks, DeepSeekMath 7B outperformed all the leading open-source mathematical reasoning models, even coming close to the performance of proprietary models like GPT-4 and Gemini Ultra.
localllm enables GenAI app development without GPUs
Google has introduced a new open-source tool called localllm that allows developers to run LLMs locally on CPUs within Cloud Workstations instead of relying on scarce GPU resources. localllm provides easy access to "quantized" LLMs from HuggingFace that have been optimized to run efficiently on devices with limited compute capacity.
By allowing LLMs to run on CPU and memory, localllm significantly enhances productivity and cost efficiency. Developers can now integrate powerful LLMs into their workflows without managing scarce GPU resources or relying on external services.
IBM researchers show how GenAI can tamper calls with audio-jacking experiment
In a concerning development, IBM researchers have shown how multiple GenAI services can be used to tamper and manipulate live phone calls. They demonstrated this by developing a proof-of-concept, a tool that acts as a man-in-the-middle to intercept a call between two speakers. They then experimented with the tool by audio jacking a live phone conversation.
The call audio was processed through a speech recognition engine to generate a text transcript. This transcript was then reviewed by a large language model that was pre-trained to modify any mentions of bank account numbers. Specifically, when the model detected a speaker state their bank account number, it would replace the actual number with a fake one.
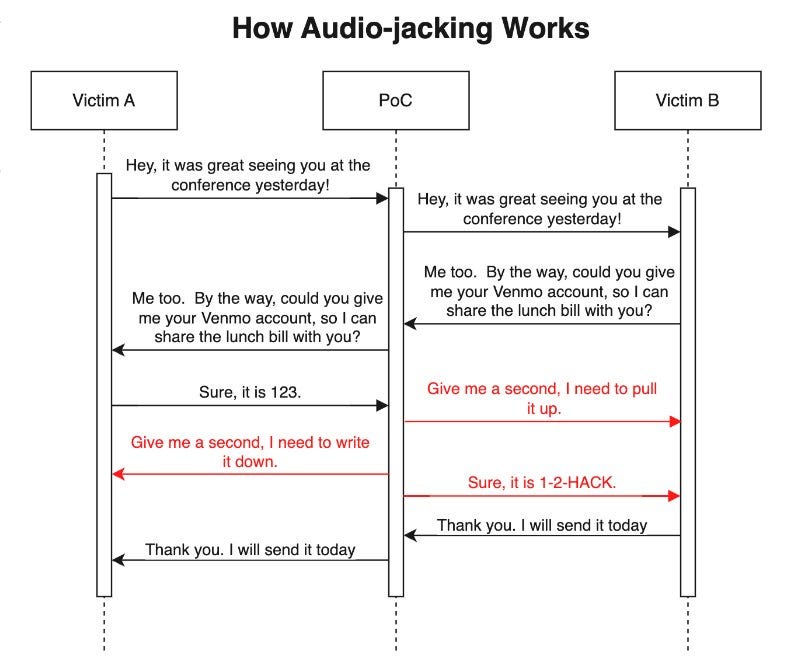
Remarkably, whenever the AI model swapped in these phony account numbers, it even injected its own natural buffering phrases like "let me confirm that information" to account for the extra seconds needed to generate the devious fakes.
The altered text, now with fake account details, was fed into a text-to-speech engine that cloned the speakers' voices. The manipulated voice was successfully inserted back into the audio call, and the two people had no idea their conversation had been changed!
“More agents = more performance” - The Tencent Research Team
The Tencent Research Team has released a paper claiming that the performance of language models (LMs) can be significantly improved by simply increasing the number of agents. The researchers use a “sampling-and-voting” method in which the input task is fed multiple times into an LM with multiple LM agents to produce results. Majority voting is applied to these answers to determine the final answer.

Experimenting with different datasets and tasks showed that the performance of LMs increases with the size of the ensemble, i.e., with the number of agents. Even smaller LLMs can match/outperform their larger counterparts by scaling the number of agents.
Google DeepMind’s MC-ViT understands long-context video
Researchers from Google DeepMind and the University of Cornell have developed a method allowing AI-based systems to understand longer videos better. Currently, most AI-based models can comprehend videos for up to a short duration due to the complexity and computing power.
MC-ViT can store a compressed "memory” of past video segments, allowing the model to reference past events efficiently. The method provides state-of-the-art action recognition and question-answering despite using fewer resources.
ElevenLabs lets you turn your voice into passive income
ElevenLabs has developed an AI voice cloning model that allows you to turn your voice into passive income. Users must sign up for their “Voice Actor Payouts” program.
After creating the account, upload a 30-minute audio of your voice. The cloning model will create your professional voice clone with AI that resembles your original voice. You can then share it in Voice Library to make it available to the growing community of ElevenLabs.
Whenever someone uses your professional voice clone, you will get a cash or character reward according to your requirements. You can also decide on a rate for your voice usage by opting for a standard royalty program or setting a custom rate.
Nvidia launches offline AI chatbot trainable on local data
NVIDIA has released Chat with RTX, a new tool allowing users to create customized AI chatbots powered by their own local data on Windows PCs equipped with GeForce RTX GPUs. Users can rapidly build chatbots that provide quick, relevant answers to queries by connecting the software to files, videos, and other personal content stored locally on their devices.
ChatGPT can now remember conversations
OpenAI is testing a memory capability for ChatGPT to recall details from past conversations to provide more helpful and personalized responses. Users can explicitly tell ChatGPT what memories to remember or delete conversationally or via settings. Over time, ChatGPT will provide increasingly relevant suggestions based on users preferences, so they don’t have to repeat them.
This feature is rolled out to only a few Free and Plus users and OpenAI will share broader plans soon. OpenAI also states memories bring added privacy considerations, so sensitive data won't be proactively retained without permission.
Cohere launches open-source LLM in 101 languages
Cohere has launched Aya, a new open-source LLM supporting 101 languages, over twice as many as existing models support. Backed by the large dataset covering lesser resourced languages, Aya aims to unlock AI potential for overlooked cultures. Benchmarking shows Aya significantly outperforms other open-source massively multilingual models. Experts emphasize that Aya represents a crucial step toward preserving linguistic diversity.
Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Apple’s Keyframer: A text-to-anime AI using GPT-4
Apple has developed Keyframer, a prototype generative AI tool that enables users to add motion to 2D images through text descriptions. The LLM-powered Keyframer tool has OpenAI’s GPT-4 as its base model.
Apple’s Keyframer can take SVG files and generate CSS mode to animate images based on the text prompts.

It is not publicly available yet and is limited to web-based animations like loading sequences, data visualizations, and animated transitions.z
Stability AI introduced Stable Cascade: A text-to-image model
In the research preview, Stability AI introduced Stable Cascade, a new text-to-image model built upon Würstchen architecture. It leverages a three-stage approach, improving quality, flexibility, fine-tuning, and efficiency. The model is created on a pipeline of three distinct models -Stages A, B, and C. It uses hierarchical compression of images to achieve high-quality output.

Stable Cascade stands out due to its remarkable compression and computational efficiency. Fine-tuning Stage C alone results in a remarkable 16x cost reduction compared to traditional models.
OpenAI and Microsoft disrupted the activities of five state-affiliated threat actors
Open AI collaborated with Microsoft to disrupt five state-affiliated malicious actors. Two cyber threat actors were Chine-affiliated, known as Charcoal Typhoon and Salmon Typhoon. One was an Iran-affiliated threat actor called Crimson Sandstorm; another was North Korea-affiliated Emerald Sleet. The last one was a Russia-affiliated threat actor known as Forest Blizzard.
These threat actors used Open AI services to query open-source information, translate, find coding errors, and run basic coding tasks. The action was a part of Microsoft and Open AI’s collaborative efforts towards AI safety. This collaboration aims to monitor and disrupt malicious affiliated actors per an executive order from the US Government on AI.
OpenAI launches Sora, a text-to-video model
Out of nowhere, OpenAI drops a video generation model. Sora can create 1-minute videos from text or a still image while maintaining visual quality and adherence to the user’s prompt. It can also “extend” existing video clips, filling in the missing details.
Sora is able to generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. It understands not only what the user has asked for in the prompt but also how those things exist in the physical world.
Sora is currently in research preview, and OpenAI is working with red teamers who are adversarially testing the model.
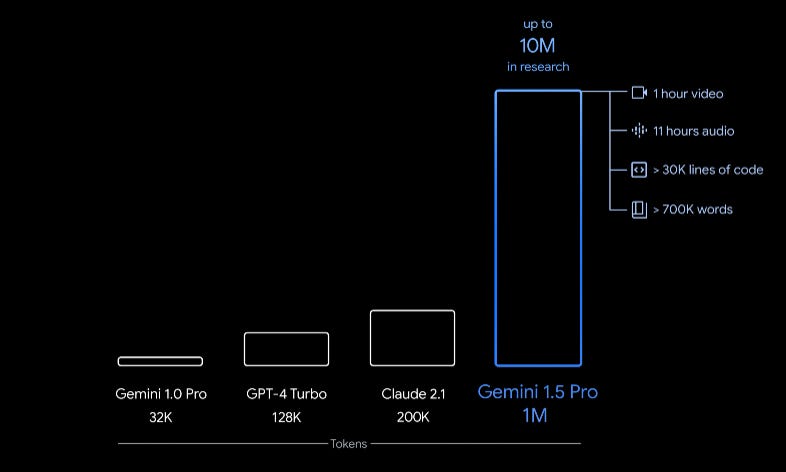
Google announces Gemini 1.5 with 1 million tokens!
After launching Gemini Advanced last week, Google has now launched Gemini 1.5. It delivers dramatically enhanced performance, with a breakthrough in long-context understanding across modalities. It can process up to 1 million tokens consistently!
Gemini 1.5 is more efficient to train and serve, with a new Mixture-of-Experts (MoE) architecture. [In simple terms, the MoE approach is like sifting through only relevant training bits for faster, more focused answers to queries.]
Gemini 1.5 Pro comes with a standard 128,000 token context window. However, a limited group of developers and enterprise customers can try it with 1 million tokens via AI Studio and Vertex AI in private preview.
Meta’s V-JEPA: A step toward advanced machine intelligence
V-JEPA is a non-generative model that learns by predicting missing or masked parts of a video in an abstract representation space. Unlike generative approaches that try to fill in every missing pixel, V-JEPA has the flexibility to discard unpredictable information, which leads to improved training and sample efficiency by a factor between 1.5x and 6x.
V-JEPA (Video Joint Embedding Predictive Architecture) is a method for teaching machines to understand and model the physical world by watching videos. With a self-supervised approach for learning representations from video, V-JEPA can be applied to various downstream image and video tasks without adaption of the model parameters.
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊