


AI Weekly Rundown (December 30 to January 05)
Major AI announcements from Meta, Alibaba, Google, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
🎥 Meta's FlowVid: A breakthrough in video-to-video AI🌍 Alibaba’s AnyText for multilingual visual text generation and editing
💼 Google to cut 30,000 jobs amid AI integration for efficiency
🔍 JPMorgan announces DocLLM to understand multimodal docs
🖼️ Google DeepMind says Image tweaks can fool humans and AI
📽️ ByteDance introduces the Diffusion Model with perceptual loss
🆚 OpenAI's GPT-4V and Google's Gemini Pro compete in visual capabilities🚀 Google DeepMind researchers introduce Mobile ALOHA
💡 32 techniques to mitigate hallucination in LLMs: A systematic overview
🤖 Google’s new methods for training robots with video and LLMs
🧠 Google DeepMind announced Instruct-Imagen for complex image-gen tasks
💰 Google reportedly developing paid Bard powered by Gemini Ultra
Let’s go!
Meta's FlowVid: A breakthrough in video-to-video AI
Diffusion models have transformed the image-to-image (I2I) synthesis and are now making their way into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames.

Meta research proposes a consistent V2V synthesis method using joint spatial-temporal conditions, FlowVid. It demonstrates remarkable properties in flexibility, efficient, and high quality.
Alibaba releases AnyText for multilingual visual text generation and editing
Diffusion model based Text-to-Image has made significant strides recently. Yet, current technology for synthesizing images can still reveal flaws in the text areas in generated images.
To address this issue, Alibaba research introduces AnyText, a diffusion-based multilingual visual text generation and editing model, that focuses on rendering accurate and coherent text in the image.

Google to cut 30,000 jobs amid AI integration for efficiency
Google is considering a substantial workforce reduction, potentially affecting up to 30k employees, as part of a strategic move to integrate AI into various aspects of its business processes. The proposed restructuring is anticipated to primarily impact Google's ad sales department.
JPMorgan announces DocLLM to understand multimodal docs
DocLLM is a layout-aware generative language model designed to understand multimodal documents such as forms, invoices, and reports. It incorporates textual semantics and spatial layout information to effectively comprehend these documents.

It outperforms state-of-the-art models on multiple document intelligence tasks and generalizes well to unseen datasets.
Google DeepMind says Image tweaks can fool humans and AI
Google DeepMind’s new research shows that subtle changes made to digital images to confuse computer vision systems can also influence human perception. Adversarial images intentionally altered to mislead AI models can cause humans to make biased judgments.

This discovery raises important questions for AI safety and security research and emphasizes the need for further understanding of technology's effects on both machines and humans.
ByteDance introduces the Diffusion Model with perceptual loss
This paper introduces a diffusion model with perceptual loss, which improves the quality of generated samples. Diffusion models trained with mean squared error loss often produce unrealistic samples. Current models use classifier-free guidance to enhance sample quality, but the reasons behind its effectiveness are not fully understood.

This method improves sample quality for conditional and unconditional generation without sacrificing sample diversity.
Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
OpenAI's GPT-4V and Google's Gemini Pro compete in visual capabilities
Two new papers comprehensively compare the visual capabilities of Gemini Pro and GPT-4V, currently the most capable multimodal language models (MLLMs).
Both models perform on par on some tasks, with GPT-4V rated slightly more powerful overall. The models were tested in areas such as image recognition, text recognition in images, image and text understanding, object localization, and multilingual capabilities.
Google DeepMind researchers introduce Mobile ALOHA
Student researchers at DeepMind introduce ALOHA: 𝐀 𝐋ow-cost 𝐎pen-source 𝐇𝐀rdware System for Bimanual Teleoperation. With 50 demos, the robot can autonomously complete complex mobile manipulation tasks:
Cook and serve shrimp
Call and take elevator
Store a 3Ibs pot to a two-door cabinet
And more.
32 techniques to mitigate hallucination in LLMs: A systematic overview
New paper from Amazon AI, Stanford University, and others presents a comprehensive survey of over 32 techniques developed to mitigate hallucination in LLMs.
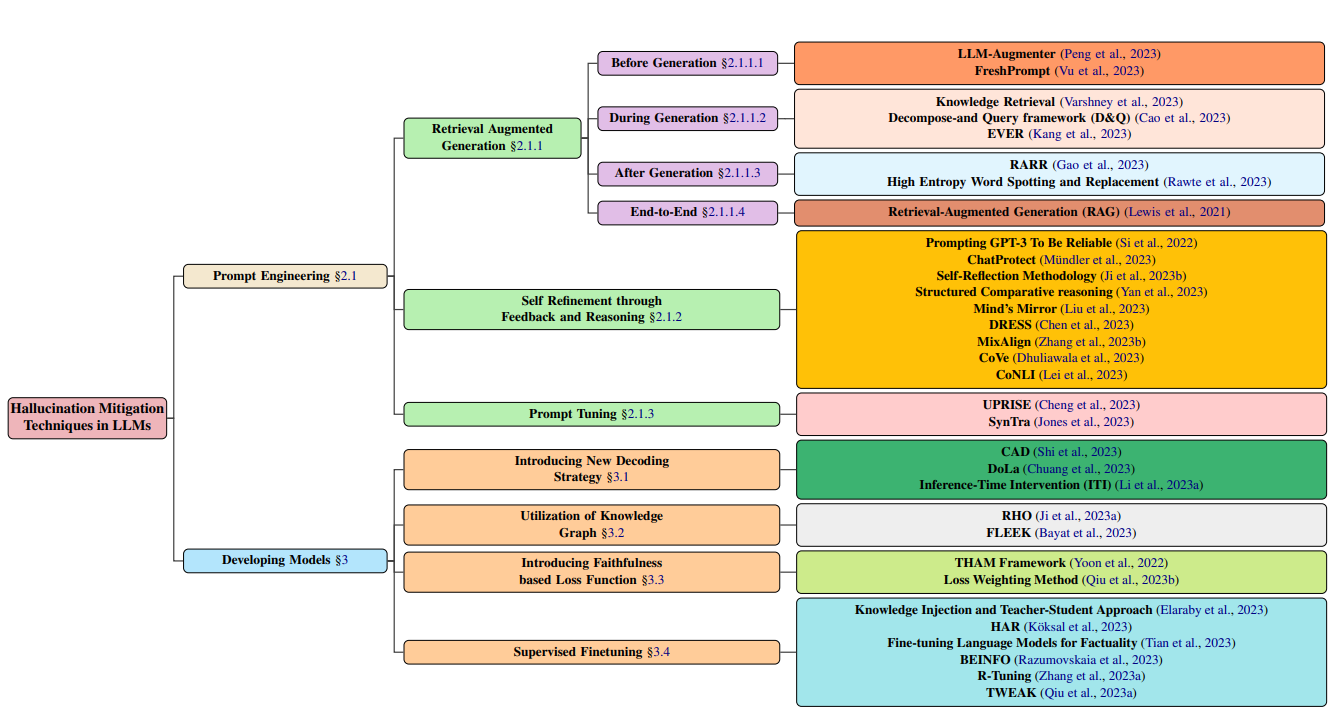
It also introduces a detailed taxonomy categorizing these methods based on various parameters, such as dataset utilization, common tasks, feedback mechanisms, and retriever types. And it analyzes the challenges and limitations inherent in these techniques.
Google’s new methods for training robots with video and LLMs
Google's DeepMind Robotics researchers have announced three advancements in robotics research: AutoRT, SARA-RT, and RT-Trajectory.
1) AutoRT combines large foundation models with robot control models to train robots for real-world tasks. It can direct multiple robots to carry out diverse tasks and has been successfully tested in various settings.
2) SARA-RT converts Robotics Transformer (RT) models into more efficient versions, improving speed and accuracy without losing quality.
3) RT-Trajectory adds visual outlines to training videos, helping robots understand specific motions and improving performance on novel tasks. This training method had a 63% success rate compared to 29% with previous training methods.
Google DeepMind announced Instruct-Imagen for complex image-gen tasks
Google released Instruct-Imagen: Image Generation with Multi-modal Instruction, a model for image generation that uses multi-modal instruction to articulate a range of generation intents. The model is built by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework.

Google reportedly developing paid Bard powered by Gemini Ultra
Google is reportedly working on an upgraded, paid version of Bard - "Bard Advanced," which will be available through a paid subscription to Google One. It might include features like creating custom bots, an AI-powered "power up" feature, a "Gallery" section to explore different topics and more. However, it is unclear when these features will be officially released.
All screenshots were leaked by @evowizz on X.
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊