


AI Weekly Rundown (April 13 to April 19)
Major AI announcements from xAI, Google, Adobe, Microsoft, Meta, and more.

Hello Engineering Leaders and AI Enthusiasts!
Another eventful week in the AI realm. Lots of big news from huge enterprises.
In today’s edition:
📊 xAI’s first multimodal model with a unique dataset
♾️ Infini-Attention: Google's breakthrough gives LLMs limitless context
⚠️ Adobe's Firefly AI trained on competitor's images: Bloomberg report
🎬 Adobe partners with OpenAI, RunwayML & Pika for Premiere Pro
🚀 Reka launches Reka Core: Their frontier in multimodal AI
🏢 OpenAI is opening its first international office in Tokyo
🎮 NVIDIA RTX A400 A1000: Lower-cost single slot GPUs
🎵 Amazon Music launches Maestro, an AI-based playlist generator
💼 Stanford’s report reflects industry dominance and rising training costs in AI
👤 Microsoft VASA-1 generates lifelike talking faces with audio
🤖 Boston Dynamics charges up for the future by electrifying Atlas
🧠 Intel reveals world's largest brain-inspired computer
🦙 Meta released two Llama 3 models; 400B+ models in training
📈 Mixtral 8x22B claims highest open-source performance and efficiency
🦈 Meta’s Megalodon to solve the fundamental challenges of the Transformer
Let’s go!
xAI’s first multimodal model with a unique dataset
xAI, Elon Musk’s AI startup, has released the preview of Grok-1.5V, its first-generation multimodal AI model. The model combines strong language understanding capabilities with the ability to process various types of visual information, like documents, diagrams, charts, screenshots, and photographs.
xAI claims Grok-1.5V has shown competitive performance across several benchmarks, including tests for multidisciplinary reasoning, mathematical problem-solving, and visual question answering. One notable achievement is its exceptional performance on the RealWorldQA dataset, which evaluates real-world spatial understanding in AI models.

Developed by xAI, this dataset features over 700 anonymized images from real-world scenarios, each accompanied by a question and verifiable answer. The release of Grok-1.5V and the RealWorldQA dataset aims to advance the development of AI models that can effectively comprehend and interact with the physical world.
Infini-Attention: Google's breakthrough gives LLMs limitless context
Google researchers have developed a new technique called Infini-attention that allows LLMs to process text sequences of unlimited length. By elegantly modifying the Transformer architecture, Infini-attention enables LLMs to maintain strong performance on input sequences exceeding 1 million tokens without requiring additional memory or causing exponential increases in computation time.
In benchmark tests on long-context language modeling, summarization, and information retrieval tasks, Infini-attention models significantly outperformed other state-of-the-art long-context approaches while using up to 114 times less memory.
Adobe's Firefly AI trained on competitor's images: Bloomberg report
In a surprising revelation, Adobe's AI image generator Firefly was found to have been trained not just on Adobe's own stock photos but also on AI-generated images from rival platforms like Midjourney and DALL-E. The Bloomberg report, which cites insider sources, notes that while these AI images made up only 5% of Firefly's training data, their inclusion has sparked an internal ethics debate within Adobe.
The news is particularly noteworthy given Adobe's public emphasis on Firefly's "ethical" sourcing of training data, a stance that aimed to differentiate it from competitors. Adobe had even set up a bonus scheme to compensate artists whose work was used to train Firefly. However, the decision to include AI-generated images, even if labeled as such by the submitting artists, has raised questions about the consistency of Adobe's ethical AI practices.
Adobe partners with OpenAI, RunwayML & Pika for Premiere Pro
Adobe is integrating generative AI in Premiere Pro. The company is developing its own Firefly Video Model and teaming up with third-party AI models like OpenAI's Sora, RunwayML, and Pika to bring features like Generative Extend, Object Addition and Removal, and Generative B-Roll to the editing timeline.
It will allow editors to choose the best AI models for their needs to streamline video workflows, reduce tedious tasks, and expand creativity. It also provides "Content Credentials" to track model usage.
Reka launches Reka Core: Their frontier in multimodal AI
Reka, a lesser-known AI startup has launched a new flagship offering, Reka Core - a most advanced and one of only two commercially available comprehensive multimodal solutions. It excels at understanding images, videos, and audio while offering a massive context window, exceptional reasoning skills, and even coding.
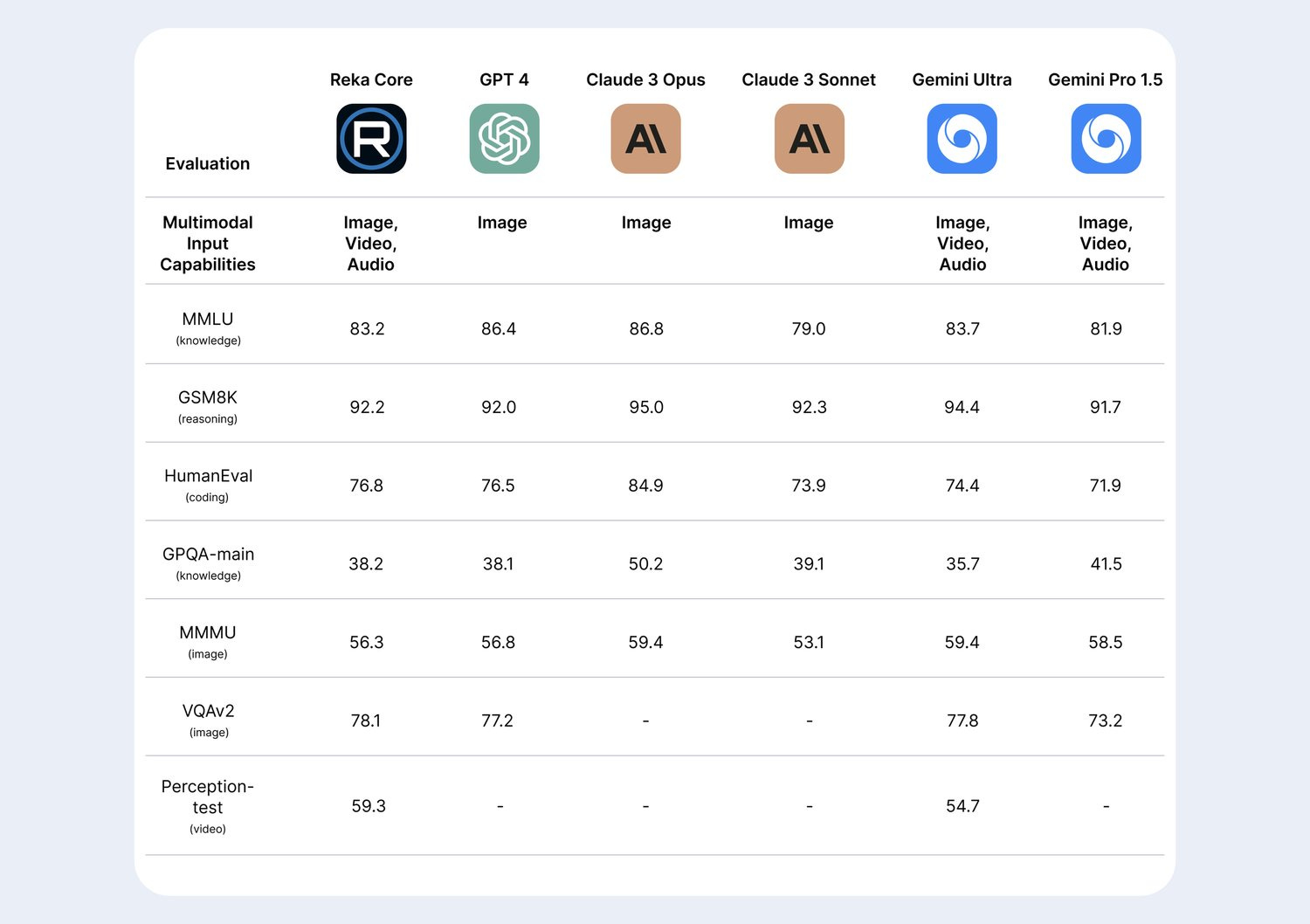
It outperforms other models on various industry-accepted evaluation metrics. Reka Core can be deployed via API, on-premises, or on-device.
OpenAI is opening its first international office in Tokyo
OpenAI is releasing a custom version of its GPT-4 model, specially optimized for the Japanese language. This specialized offering promises faster and more accurate performance and improved text handling.
Tadao Nagasaki has been appointed President of OpenAI Japan. The company plans to collaborate with the Japanese government, local businesses, and research institutions to develop safe AI tools that serve Japan’s unique needs.
NVIDIA RTX A400 A1000: Lower-cost single slot GPUs
NVIDIA is expanding its lineup of professional RTX graphics cards with two new desktop GPUs - the RTX A400 and RTX A1000. These new GPUs are designed to bring enhanced AI and ray-tracing capabilities to workstation-class computers. The RTX A1000 GPU is already available from resellers, while the RTX A400 GPU is expected to launch in May.
NVIDIA RTX A400: With 24 tensor cores for AI processing, the A400 enables professionals to run AI apps directly on their desktops, such as intelligent chatbots and copilots. It allows creatives to produce vivid, physically accurate 3D renderings. It also features four display outputs, making it ideal for high-density display environments such as financial services, command and control, retail, etc.
NVIDIA RTX A1000: With 72 Tensor Cores, the A1000 offers 3x faster generative AI processing for tools like Stable Diffusion. It excels in video processing, as it can process up to 38% more encoding streams and offers up to 2x faster decoding performance than the previous generation.
With slim single-slot design and power consumption of just 50W, both GPUs offer impressive features for compact, energy-efficient workstations.
Amazon Music launches Maestro, an AI-based playlist generator
Amazon Music is launching its AI-powered playlist generator, Maestro, following a similar feature introduced by Spotify. Maestro allows users in the U.S. to create playlists by speaking or writing prompts. The AI will then generate a song playlist that matches the user's input. This feature is currently in beta and is being rolled out to a subset of Amazon Music's free, Prime, and Unlimited subscribers on iOS and Android.
Like Spotify's AI playlist generator, Amazon has built safeguards to block inappropriate prompts. However, the technology is still new, and Amazon warns that Maestro "won't always get it right the first time."
Standford’s report reflects industry dominance and rising training costs in AI
The AI Index, an independent report by the Stanford Institute for Human-Centered Artificial Intelligence (HAI), provides a comprehensive overview of global AI trends in 2023.
The report states that the industry outpaced academia in AI development and deployment. Out of the 149 foundational models published in 2023, 108 (72.5%) were from industry compared to just 28 (18.8%) from academia.

Google (18) leads the way, followed by Meta (11), Microsoft (9), and OpenAI (7).
United States is the top source with 109 foundational models out of 149, followed by China (20) and the UK (9). In the case of machine learning models, the United States again tops the chart with 61 notable models, followed by China (15) and France (8).
Regarding AI models' training and computing costs, Gemini Ultra leads with a training cost of $191 million, followed by GPT-4, which has a training cost of $78 million.

In 2023, AI reached human performance levels in many key AI benchmarks, such as reading comprehension, English understanding, image classification, and more.

Enjoying the weekly updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you'll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Microsoft’s VASA-1 generates lifelike talking faces with audio
Microsoft Research’s groundbreaking project, VASA-1, introduces a remarkable framework for generating lifelike talking faces from a single static image and a speech audio clip.
This premiere model achieves exquisite lip synchronization and captures a rich spectrum of facial nuances and natural head motions, resulting in hyper-realistic videos.
Boston Dynamics charges up for the future by electrifying Atlas
Boston Dynamics has unveiled an electric version of their humanoid robot, Atlas. Previously powered by hydraulics, the new Atlas operates entirely on electricity. This development aims to enhance its strength and range of motion, making it more versatile for real-world applications.
Boston Dynamics also plans to collaborate with partners like Hyundai to test and iterate Atlas applications in various environments, including labs, factories, and everyday life.
Intel reveals world's largest brain-inspired computer
Intel has introduced the world’s largest neuromorphic computer, mimicking the human brain. Unlike traditional computers, it combines computation and memory using artificial neurons. With 1.15 billion neurons, it consumes 100 times less energy than conventional machines. It performs 380 trillion synaptic operations per second This breakthrough could revolutionize AI and enhance energy-efficient computing.
Meta’s Llama 3 models are here; 400B+ models in training!
Llama 3 is finally here! Meta introduced the first two models of the Llama 3 family for broad use: pretrained and instruction-fine-tuned language models with 8B and 70B parameters. Meta claims these are the best models existing today at the 8B and 70B parameter scale, with greatly improved reasoning, code generation, and instruction following, making Llama 3 more steerable.

But that’s not all. Meta is also training large models with over 400B parameters. Over coming months, it will release multiple models with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities.
Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
Mixtral 8x22B claims highest open-source performance and efficiency
Mistral AI has unveiled Mixtral 8x22B, a new open-source language model that the startup claims achieves the highest open-source performance and efficiency. it’s sparse mixture-of-experts (SMoE) model actively uses only 39 billion of its 141 billion parameters. As a result, it offers an exceptionally good price/performance ratio for its size.
The model’s other strengths include multilingualism, with support for English, French, Italian, German, and Spanish, as well as strong math and programming capabilities.
Meta’s Megalodon to solve the fundamental challenges of the Transformer
Researchers at Meta and the University of Southern California have proposed a new model that aims to solve some of the fundamental challenges of the Transformer, the deep learning architecture that gave rise to the age of LLMs.
The model, Megalodon, allows language models to extend their context window to millions of tokens without requiring huge amounts of memory. Experiments show that Megalodon outperforms Transformer models of equal size in processing large texts. The researchers have also obtained promising results on small– and medium-scale experiments on other data modalities and will later work on adapting Megalodon to multi-modal settings.
That's all for now!
Subscribe to The AI Edge and gain exclusive access to content enjoyed by professionals from Moody’s, Vonage, Voya, WEHI, Cox, INSEAD, and other esteemed organizations.
Thanks for reading, and see you on Monday. 😊